앞의 포스트에서 liked list에 대하여 설명이 되었을것이다. hashtable은 무한의 데이터의 영역을 제한된 영역으로 표현하여 data를 저장할 수 있도록한다.
hashtable에서는 무한의 데이터를 key라고 하는데 hashFuction을 통해 key를 유한한 데이터(hash)로 바꾸어 저장하여준다.
예를 들어 아래와 같은 hash 가 0-9 까지의 유한한 데이터를 가질 수 있도록 짜여진 hashFuction 이라면
void hashFunc (int key){
int hash = key%10; //key값을 10으로 나눈 나머지
return hasy;
}
key값이 211,301,121, 이라면 이 key값에 대한 hash값은 모두 1이 될것이다.
이런식으로 무한한 값을 유한한 값으로 표현하여 저장하는 것이 hashtable이다.
hashtable에서의 삽입과 삭제 검색 등은 모두 key의 값을 이용하여 실행 할 수 있다.
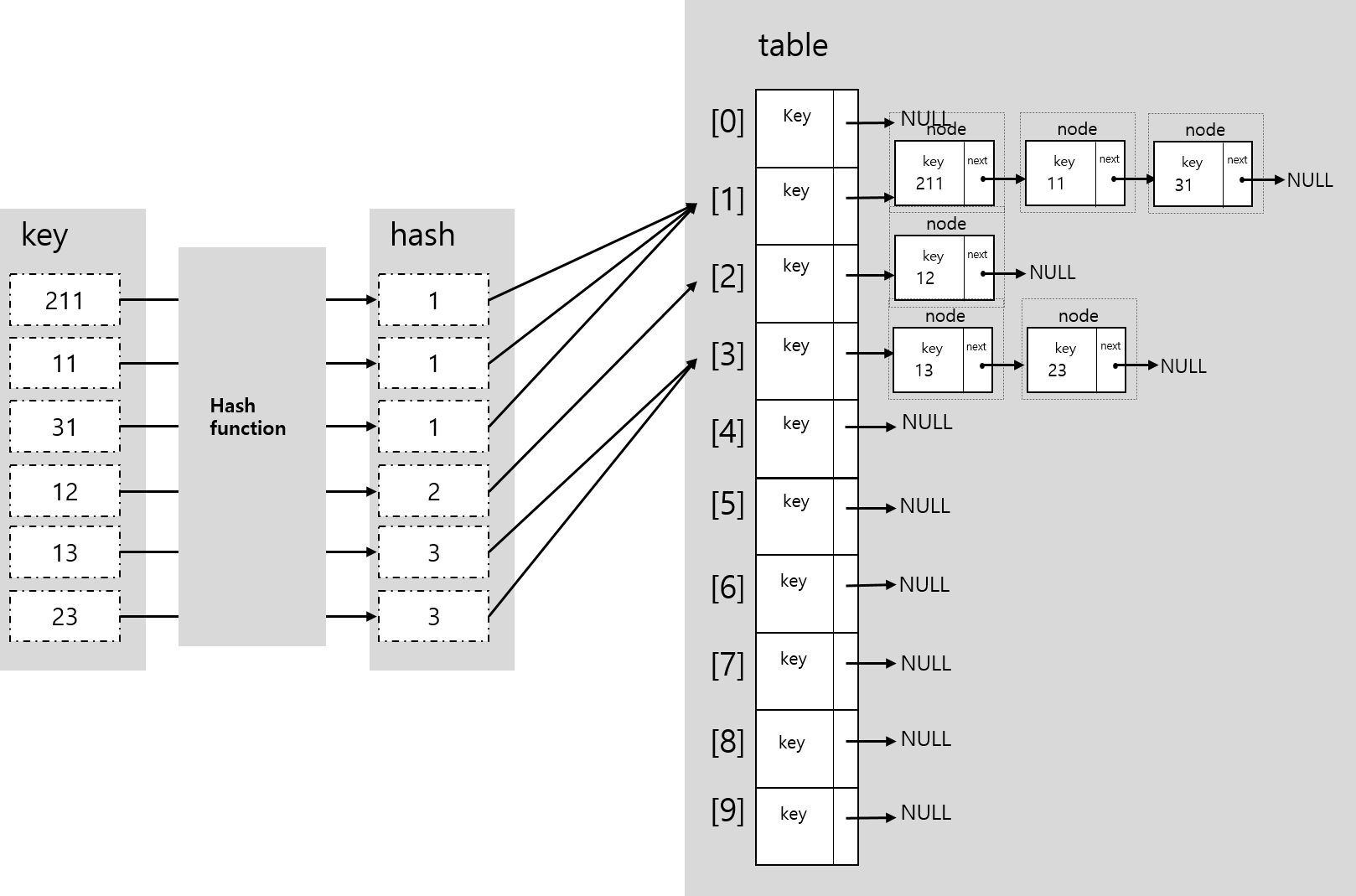
Hash 충돌
앞의 예시와 같이 key의 값이 211,301,121 이라면 hash값은 모두 1이 될것이다. 3개의 데이터가 모두 한 곳에 저장되려 한다면 충돌이 일어날 것이다. 이러한 hash충돌을 보완하여 hashtable을 만드는 방법으로 Chaining방식과 Open Addressing방식이 있는데 (Open Addressing 은 자세히 모른다..) 이번 hashTable을 구현함에 있어 Chaining 방식을 사용하였다.
chaining
-아래의 그림과 같이 충돌되는 데이터들을 다른 메모리에 할당하여 linked list처럼 연결해주는 방식이다.
 </img>
</img>
###hashtable 코드분석 (linked list와 중복되는 부분에 대한 설명은 간략히하였다.)
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define MAX_TBL 10
#define STR_LEN 50
struct InfoNode {
int key;
struct InfoNode * next;
};
struct Table {
struct InfoNode tbl[MAX_TBL];
};
-node와 table을 정의해준다. 이 때 table은 hash를 저장할 배열로 정의하였다.
int hashFunc(int key) {
return key % 10;
}
//hashFunction으로 0-9까지의 값으로 한정하여준다.
void initTable(struct Table * t) {
int i;
for (i=0; i < MAX_TBL; i++) {
(t->tbl[i]).key = 0;
(t->tbl[i]).next = NULL;
}
}
//table의 값을 초기화해준다.
-무한한 key의 값을 0-9까지의 값으로 한정시켜주는 hashFunction 함수를 만들어준다. 그리고 0-9의 hash의 값을 저장할 table을 모두 초기화 시켜준다.
char * searchTable(struct Table * t, int key) {
int hKey = hashFunc(key);
if ((t->tbl[hKey]).key == key) {//2
return (t->tbl[hKey]).key;
}
else { //3
struct InfoNode * node = (t->tbl[hKey]).next;
while(node != NULL) {
if(node->key == key) {//4
return node->key;
}
node = node->next;
}
}
return NULL; //5
}
-key의 값을 이용해서 같은 key를 가진 노드를 찾아주는 함수이다. 먼저 key에 대한 hash를 찾아준 뒤
node포인터를 이용해 연결된 노드를 모두 지나면서 같은 key를 가진 노드를 return 한다.
struct InfoNode * createNode(int key) { //6
struct InfoNode * newNode;
newNode = (struct InfoNode *) malloc(sizeof(struct InfoNode));
newNode->key = key;
newNode->next = NULL;
return newNode;
}
void insertNext(struct InfoNode *curr, int key) { //7
struct InfoNode * newNode;
newNode = createNode(key);
newNode->next = curr->next;
curr->next = newNode;
}
-key값을 저장한 노드를 만드는 함수 -다음노드에 연결 (linked list와 같음)
void insertTable(struct Table * t, int key) { //8
int hKey = hashFunc(key);
if (searchTable(t, key) != NULL) {
printf("Error! duplicated keys!\n");
}
else {
insertNext(&t->tbl[hKey], key);
}
}
-key값에 대한 hash를 찾아 배열에 저장하는 함수. -이 때 insertNext함수를 사용하여 해쉬충돌이 일어나지 않도록 같은 index의 배열에 데이터가 존재할 때 다음노드로 연결하여 linked list를 구현하여준다. -만약 같은 key를 가진 값이 있으면 에러 메세지를 출력한다.
char * deleteTable(struct Table * t, int key) {
int hKey = hashFunc(key);
struct InfoNode *head;//hashFunc함수를 이용하여 hkey값을 가져온다.
struct InfoNode * node = (t->tbl[hKey]).next;
struct InfoNode *curr = (t->tbl[hKey]).next;
//t->tbl[hkey]의 next값(등록된 값들)을 가리키는 포인터를 두개 만들어준다.
while(node != NULL) {
if (node->key == key) {//4
if((node->key)==(t->tbl[hKey]).next->key){
t->tbl[hKey].next=node->next;
}
//node는 tbl배열에서 next로 넘어가면서 인자로 받은 key값과 같은 값이 있으면 그 전의
//노드와 그 다음의 노드를 연결하여 같은 key값을 가진 노드의 연결을 끊어 없애준다.
//이때 첫번째 노드는 tbl[hkey]의 next이므로 이를 이용하여 첫번 째 노드인지를 찾고 연결을 끊어준다.
else{
while(curr->next!=node){
curr->next=node->next;
curr=curr->next;
}
}
//key값이 같은 노드를 node포인터로 찾고 그 전 노드와 없앨 노드의 다음노드를 연결해주기 위해
//그 전 노드를 curr포인터로 가리킨다. 그 후 curr의 next를 없앨 노드의 다음노드로 연결해준다.
node->next=NULL;
}
node=node->next;
}
}
-노드 삭제 함수.
/*
void insertSort(struct Table * t)
{
struct InfoNode *curr,*p,*head;
for(int i=0; i<10; i++){
head=t->tbl[i].next;
curr=t->tbl[i].next;
p=NULL;
while(curr->next!=NULL){
if(curr->key>curr->next->key){
p=curr->next;
curr->next=curr->next->next;
p->next=head;
head=p;
curr=p;
}
else{
curr=curr->next;
}
}
}
printf("inserSort result:");
printAll(t);
}
*/
-값을 오름차순으로 정렬해주는 함수, key값에 대한 hash를 찾은 후 이에 대응하는 배열의 linked list에서 이전에 사용했던 정렬 함수를 응요하여보았으나
실행이 되지 않았다. 차차 수정할 계획.
void printAll(struct Table * t){
for(int i=0; i<10; i++){
struct InfoNode *node;
node=(t->tbl[i]).next;
printf("hashtable[%d]:",i);
while(node!=NULL){
printf("->%d",node->key);
node=node->next;
}
printf("\n");
}
}
-linked list와는 달리 table 배열에 연결되어있는 모든 노드를 출력해야하므로 배열을 도는 반복문 하나 연결된 linked list를 도는 반복문 하나, 총 두개의 반복문을 사용하여 모든 노드를 출력하게 하였다.
int main(int argc, const char * argv[]) {
struct Table myTable;
initTable(&myTable);
insertTable(&myTable, 9001);
insertTable(&myTable, 8001);
insertTable(&myTable, 7001);
insertTable(&myTable, 9002);
insertTable(&myTable, 9003);
insertTable(&myTable, 9124);
insertTable(&myTable, 9013);
insertTable(&myTable, 9021);
insertTable(&myTable, 9011);
insertTable(&myTable, 9024);
//key값 입력
printAll(&myTable);
//table의 모든 값 출력
printf("--------------\n");
deleteTable(&myTable,9002); //9002를 삭제
printAll(&myTable);
//삭제가 잘 되었는지 보기위해 table의 모든 값 출력
//insertSort(&myTable);
return 0;
}
전체코드
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define MAX_TBL 10
#define STR_LEN 50
struct InfoNode {
int key;
struct InfoNode * next;
};
struct Table {
struct InfoNode tbl[MAX_TBL];
};
int hashFunc(int key) {
return key % 10;
}
void initTable(struct Table * t) {
int i;
for (i=0; i < MAX_TBL; i++) {
(t->tbl[i]).key = 0;
(t->tbl[i]).next = NULL;
}
}
char * searchTable(struct Table * t, int key) {
int hKey = hashFunc(key);
if ((t->tbl[hKey]).key == key) {//2
return (t->tbl[hKey]).key;
}
else { //3
struct InfoNode * node = (t->tbl[hKey]).next;
while(node != NULL) {
if(node->key == key) {//4
return node->key;
}
node = node->next;
}
}
return NULL; //5
}
struct InfoNode * createNode(int key) { //6
struct InfoNode * newNode;
newNode = (struct InfoNode *) malloc(sizeof(struct InfoNode));
newNode->key = key;
newNode->next = NULL;
return newNode;
}
void insertNext(struct InfoNode *curr, int key) { //7
struct InfoNode * newNode;
newNode = createNode(key);
newNode->next = curr->next;
curr->next = newNode;
}
void insertTable(struct Table * t, int key) { //8
int hKey = hashFunc(key);
if (searchTable(t, key) != NULL) {
printf("Error! duplicated keys!\n");
}
else {
insertNext(&t->tbl[hKey], key);
}
}
char * deleteTable(struct Table * t, int key) {
int hKey = hashFunc(key);
struct InfoNode *head;
struct InfoNode * node = (t->tbl[hKey]).next;
struct InfoNode *curr = (t->tbl[hKey]).next;
while(node != NULL) {
if (node->key == key) {//4
if((node->key)==(t->tbl[hKey]).next->key){
t->tbl[hKey].next=node->next;
}
else{
while(curr->next!=node){
curr->next=node->next;
curr=curr->next;
}
}
node->next=NULL;
}
node=node->next;
}
}
/*
void insertSort(struct Table * t)
{
struct InfoNode *curr,*p,*head;
for(int i=0; i<10; i++){
head=t->tbl[i].next;
curr=t->tbl[i].next;
p=NULL;
while(curr->next!=NULL){
if(curr->key>curr->next->key){
p=curr->next;
curr->next=curr->next->next;
p->next=head;
head=p;
curr=p;
}
else{
curr=curr->next;
}
}
}
printf("inserSort result:");
printAll(t);
}
*/
void printAll(struct Table * t){
for(int i=0; i<10; i++){
struct InfoNode *node;
node=(t->tbl[i]).next;
printf("hashtable[%d]:",i);
while(node!=NULL){
printf("->%d",node->key);
node=node->next;
}
printf("\n");
}
}
int main(int argc, const char * argv[]) {
struct Table myTable;
initTable(&myTable);
insertTable(&myTable, 9001);
insertTable(&myTable, 8001);
insertTable(&myTable, 7001);
insertTable(&myTable, 9002);
insertTable(&myTable, 9003);
insertTable(&myTable, 9124);
insertTable(&myTable, 9013);
insertTable(&myTable, 9021);
insertTable(&myTable, 9011);
insertTable(&myTable, 9024); //10
printAll(&myTable);
printf("--------------\n");
deleteTable(&myTable,9002);
printAll(&myTable);
//insertSort(&myTable);
return 0;
}
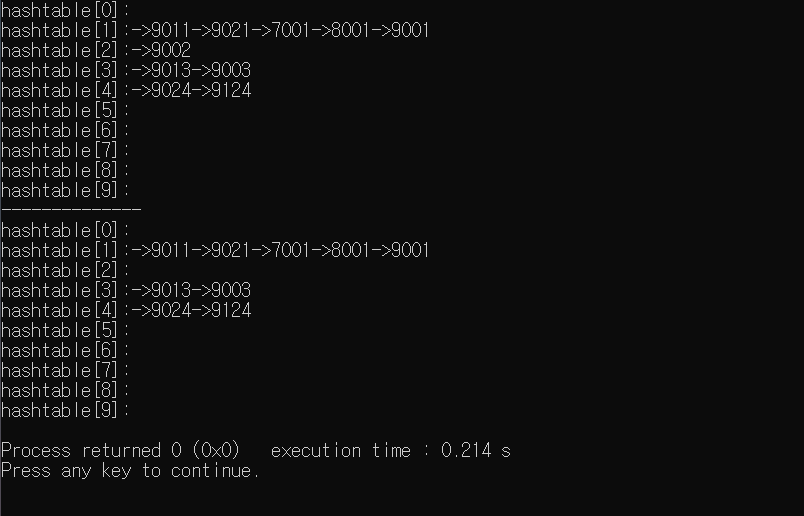
코드실행결과
 </img>
</img>
정렬부분에 오류가 있어서 아쉽다.. 다음에 수정하면서 안되었던 이유도 같이 업로드 할 예정 !