[paper review] A Machine-Learning-based Data Classifier to Reduce the Write Amplification in SSDs
15 Aug 2022
Reading time ~5 minutes
이번에는 A Machine-Learning-based Data Classifier to Reduce the Write Amplicfiation in SSDs를 리뷰해보려고 한다. 저자는 Yi-Ying Lu, Jchin-Hsien Wu∗, Ya-Shu Chen 이며 ACM ISBN 에 발표된 논문이다.
1 INTRODUCTION
SSD란
SSD란 (Solid-state drives) 간단히 비휘발성 저장장치를 말한다. SSD는 컨트롤러와 낸드 플래시 메모리, DRAM(캐시)로 구성되어 있다.
- SSD컨트롤러 : 플래시 메모리에 데이터를 저장, 메모리를 관리, 데이터를 다시 읽는 것 까지 모든 것을 하는 핵심 부품
- 낸드 플래시 메모리 : 데이터가 저장되어있는 곳
- DRAM : 캐시
SSD는 페이지, 블록, 플레인 단위로 이루어져 있는데,
- 페이지 (Page) : 낸드 플래시 메모리에서 데이터 저장의 기본단위로 읽기, 쓰기 작업의 최소 단위이다.
- 블록 (Block) : 페이지의 집합을 나타내며 지우기 작업의 최소 단위이다. 즉 SSD의 내용을 지울 때는 블록 단위로 지우는 것이다.
- 플레인 (Plane) : 블록의 집합으로, 연산 처리의 단위이다.
SSD에서는 데이터 덮어쓰기가 불가능하기 때문에 중복되는 데이터가 업데이트 될 때 덮어쓰는게 아니라 새 페이지에 기록되고 이전 페이지는 invalid 페이지가 된다.
GC(garbage collection)
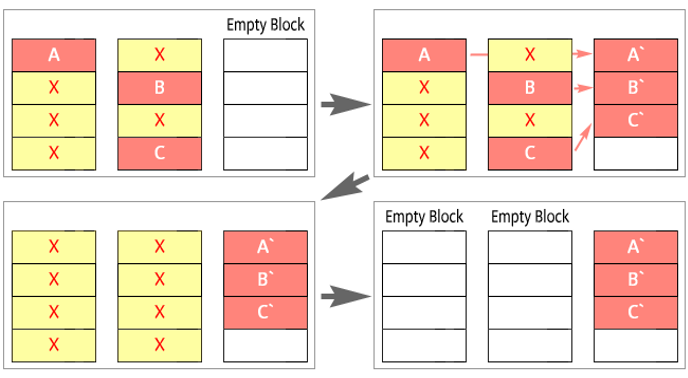
GC는 페이지를 정리하는 기능이다.
SSD에 데이터를 쓸 공간이 부족하지 않게 SSD는 필요하지 않은 페이지(invalid 페이지라고 표현)를 지우면서 페이지를 정리해주는 GC을 주기적으로 수행한다. 사용가능한 페이지 수가 충분하지 않거나, invalid 페이지가 늘어나면 GC을 수행하게 되는데 SSD는 데이터를 지울 때 페이지단위로 지우는것이 아니라 블록 단위로 지울 수 있기 때문에 필요한 데이터(valid 데이터)는 빈 블록(Empty Block)에 복사하여 해당 블록을 지운다.
WA(write Amplication)

write Amplication은 SSD의 성능을 측정하는 대표적인 지표이다.
내부의 추가적인 읽기 쓰기 오버헤드가 얼만큼인지를 나타내며 값이 클수록 오버헤드가 크다는 의미이기 때문에 성능이 저하된다.
Hot data Cold data

Hot data는 자주 업데이트 되는 데이터이고, Cold data는 자주 업데이트 되지 않는 데이터를 나타낸다.
최근 ssd의 WA을 줄이기 위해 처음 데이터를 쓸 때부터 Hot data Cold data를 분류하여 Hot data는 Hot data끼리, Cold data는 Cold data끼리 같은 블록에 쓰려는 시도가 많아지고 있다. GC를 통해 invalid 페이지를 지우기 위해서는 블록 단위로 페이지를 지워야 하는데 이 때 지워야 하는 블록에 invalide 페이지와 valid 페이지가 많이 섞여 있을수록 다른 블록으로 옮겨야 하는 페이지의 수가 많아지므로 추가적인 쓰기 오버헤드, 즉 WA가 커지면서 성능이 저하된다. 만약 invalid 페이지가 같은 블록에 모여있다면 해당 블록에서 다른 블록으로 페이지를 옮길 필요없이 블록을 지우기만 하면 되므로 WA가 감소하여 성능이 좋아진다. 그래서 invalid 페이지가 많이 생기는 Hot blockr과 invalid 페이지가 많이 생기지 않는 cold block을 분류하여 WA를 감소시키려는 연구가 많이 진행 되고있다.
본 논문에서는 머신러닝을 이용하여 SSD에 써지는 데이터들을 비지도 학습이자 데이터 분류, 데이터 군집화 알고리즘인 K-means을 통해 Hot data와 Cold data로 분류하고자 한다.
2 BACKGROUND
Hot, Cold 데이터 분류 알고리즘에는 Two-Level_LRU, WDAC, mBFs, DAC 등이 있다.
Two-Level-LRU 알고리즘
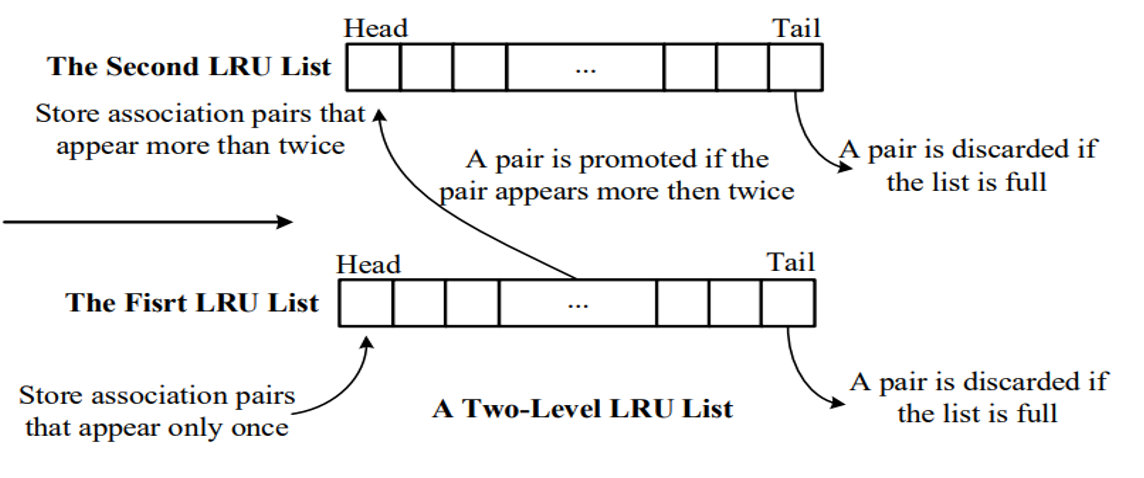
Two-Level-LRU List는 request가 있을 때 candidate list에 삽입을 하고 만약 짧은 시간안에 같은 Logical Address가 다시 요청되면 candidate list에 있던 데이터가 Hot List에 옮겨지면서 Hot data와 Cold data를 분류하는 알고리즘이다.
WDAC (window-based direct address counting)알고리즘

WDAC 알고리즘은 window 에서 들어온 요청과 같은 요소를 검색하여 LA의 쓰기 거리와 빈도수를 얻고, 그림과 같이 빈도수와 거리의 가중치에 의해 LA의 heat score를 계산한다. window는 과거의 어디까지 참조할 것인지를 나타내는 범위이며 0~9 숫자와 같이 거리에 따라 가중치를 두어 가장 먼 과거에 요청되었던 LA는 가중치를 작게, 가장 근처에 요청되었던 LA에 대해서는 가중치를 크게 두어 가중치들을 합하여 heat score를 계산한다. heat score가 클수록 Hot data 를 나타내며 window 안에서 요청되었던 빈도수가 많을 수록 더해지는 값이 많아지기 때문에 거리가 가깝고 빈도수가 많은 LA를 heat score로 계산할 수 있다.
mBFs 알고리즘
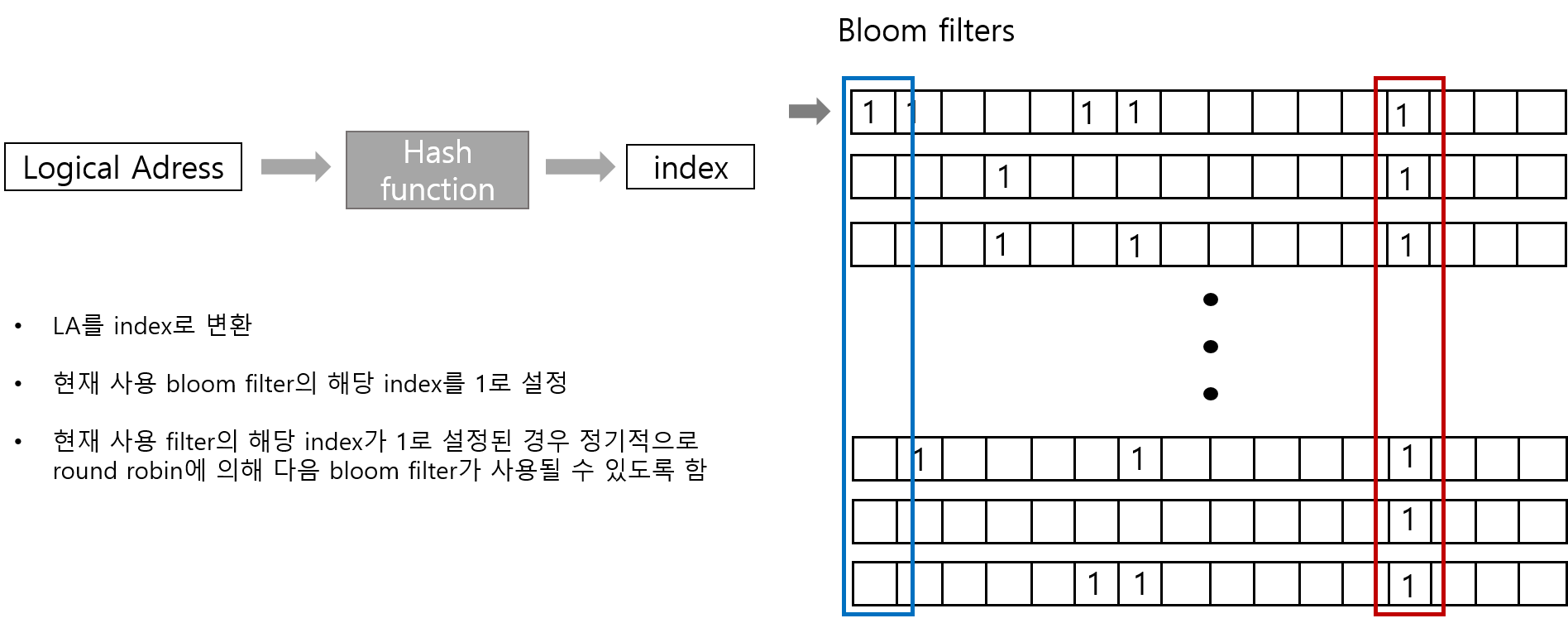
mBFs는 bloom filters를 이용한 알고리즘으로 LA를 hash function에 따라 index로 변환하고 현재 사용 bloom filter (화살표가 가리키는 곳)의 해당 index를 1로 설정한다. 현재 사용 filter의 해당 index가 1로 이미 설정된 경우는 round robin에 의해 다음 filter에서의 해당 index를 1로 설정하여 그림과 같이 1로 설정된 filter가 많은 LA를 Hot data 1로 설정된 filter가 많이 없는 LA를 cold data로 분류하는 알고리즘이다.
DAC 알고리즘
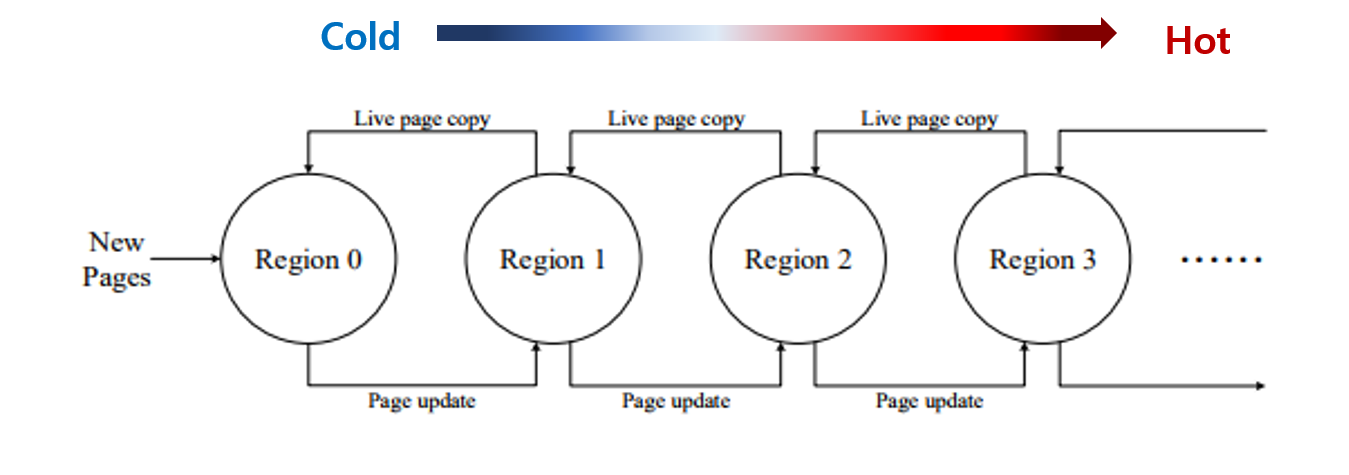
DAC알고리즘은 다른 hot data의 저장을 위해 multiple region을 사용한다. 처음 들어온 페이지는 가장 cold한 region0 에 삽입하고, 자주 업데이트 된다면 region1, region2와 같이 점점 hot한 region으로 업데이트 시키면서 hot data 와 cold data를 분류한다.

하지만 이러한 분류 알고리즘들은 대부분 고정된 임계값울 사용하기 때문에 workload 마다 특성이 변할 때 각각의 특성을 분류에 반영하지 못한다. 하지만 머신러닝을 이용한다면 임게값을 임의로 지정한 뒤 분류를 하는 것이 아니라 workload의 특성에 따라 임계값을 설정할 수 있으므로 좀 더 효율적으로 workload의 특성을 반영할 수 있는 hot data, cold data 분류가 가능하다.
4. A MACHINE LEARNINGBASED DATA CLASSIFIER TO REDUCE THE WRITE AMPLIFICATION IN SSDS
전체적인 머신러닝 기반 Hot/Cold data 분류 시스템 구조는 다음과 같다.
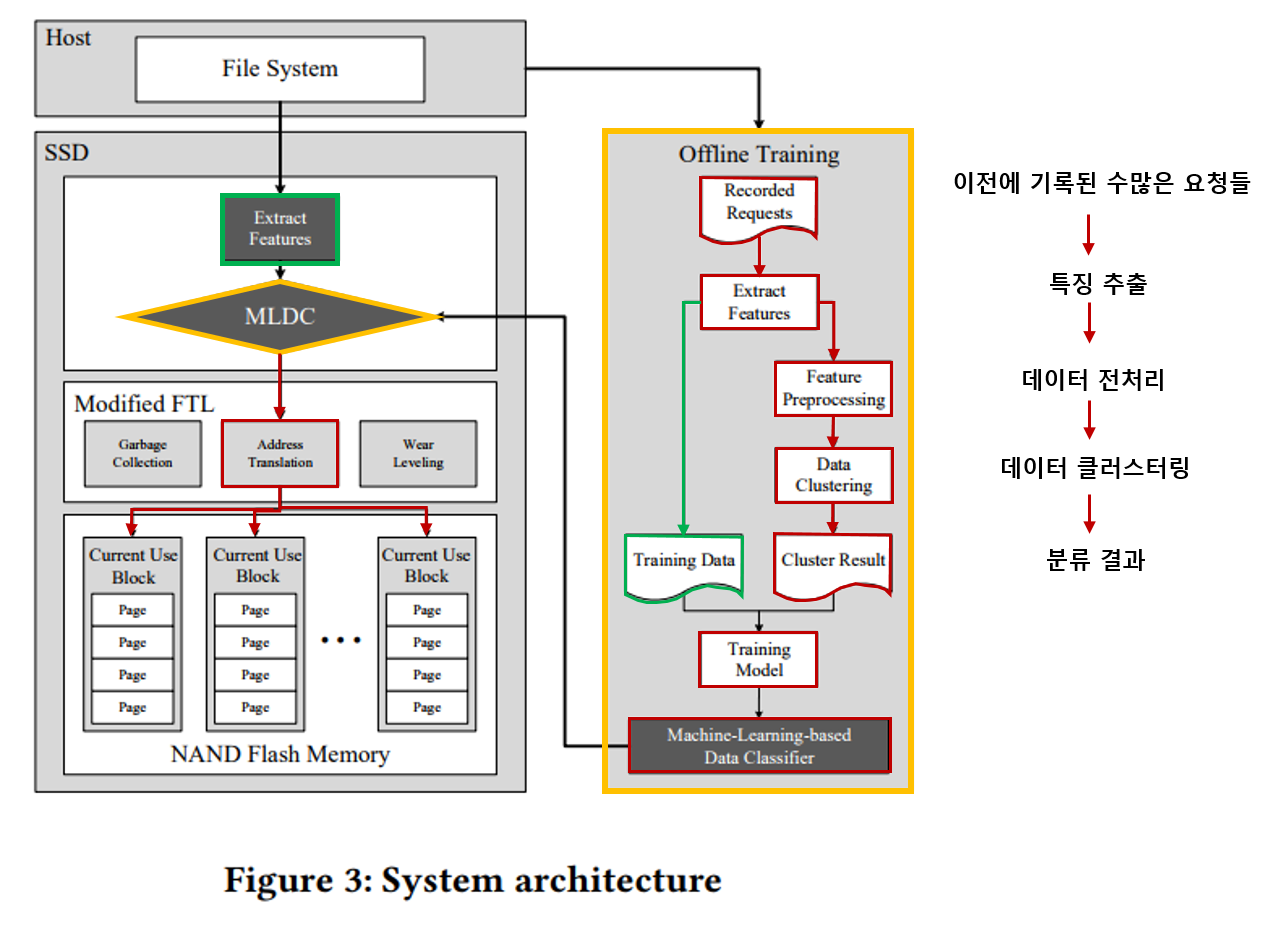
분류 모델을 학습 시키기 위해서 offline training을 수행한다.
이미 기록되어있는 과거의 request들에 대해서 * 특징을 추출, ####특징 전처리, ####데이터 클러스터링, ####클러스터 결과를 통해 모델 의 과정을 거친다. 데이터는 총 3,976의 write request중 training 데이터를 2,783개 test 데이터를 1,193개로 하여 학습하였다.
Extract Features
이미 기록되어있는 과거의 request 즉, workload에 대해서 4가지 데이터 특징을 추출한다.
- Logical address
- Size
- Write distance
- Frequence
Feature Preprocessing
이후 4가지의 특징 전처리에 대해 두가지의 전처리를 해준다.
- 정규화 - 각각의 특성의 범위를 1~00의 범위로 정규화
- 가중치 - 각각의 특성에 가중치를 같게 한다.
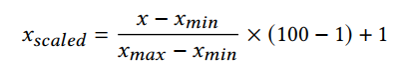
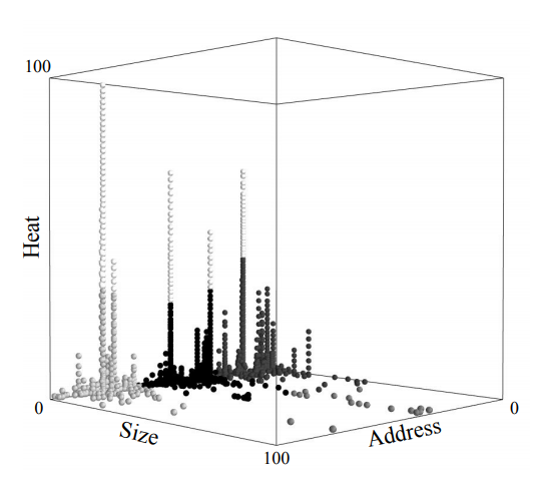
data clustering
k-means를 알고리즘을 통해 workload 특성에 따라 hot data 와 cold data를 분류한다.
k-means는 그룹과 그룹간의 적절한 경계를 찾을 수 있어 임계값을 설정하지 않아도 된다. 여기서는 몇개의 군집으로 분류할건지를 나타내는 k를 5로 설정하여 데이터를 5개의 군집으로 분류하였다.
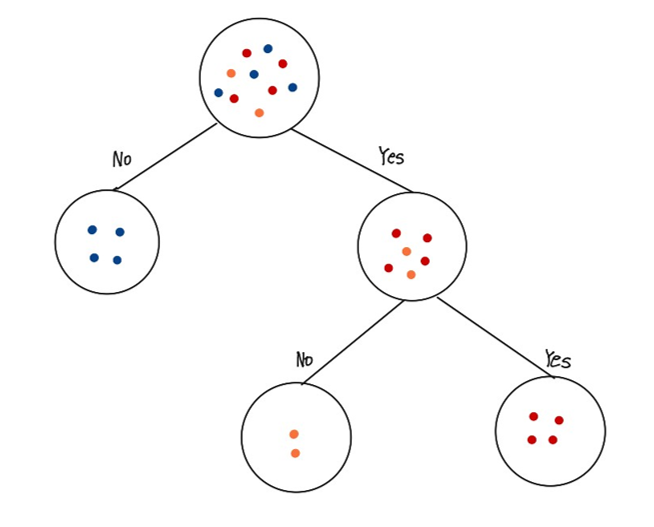
Training Model
k-means를 통해 clustering 결과에 (분류 기준) CART알고리즘에 기반한 결정트리를 사용하여 데이터의 Hot/Cold를 분류할 수 있도록 하였다.
CART알고리즘은 가장 널리 사용되는 의사결정트리 알고리즘으로 분류와 회귀에 모두 사용된다. 질문에 따라 불순도(정답에 대해 얼만큼이나 불확실한지를 나타내는 척도)가 많이 줄어드는지를 계산하고 줄어드는 폭이 큰 질문을 선택하여 분류하는 알고리즘이다.
5. EXPERIMENTS
실험 환경, 조건은 다음과 같다.
workload
- Systor17
- CASA
- MSNFS
- Microsoft Research Lab in Cambridge
- Financial
MLDC(Machine-Learning-based Data Classifier)
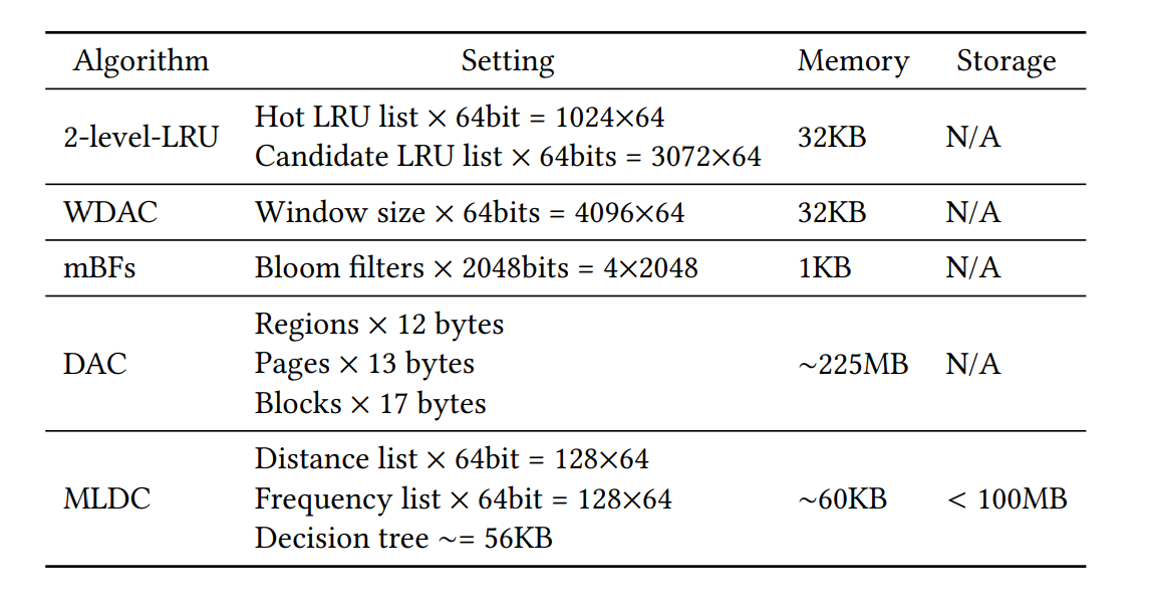
- 실험에서 request당 쓰는 페이지 수는 평균적으로 32개 정도 된다.
- 빈도수와 distance를 얻기 위해 128 길이의 list를 사용한다.
- k = 10으로 했을 때 결정 트리는 평균적으로 56KB의 메모리를 사용한다.
실험 결과
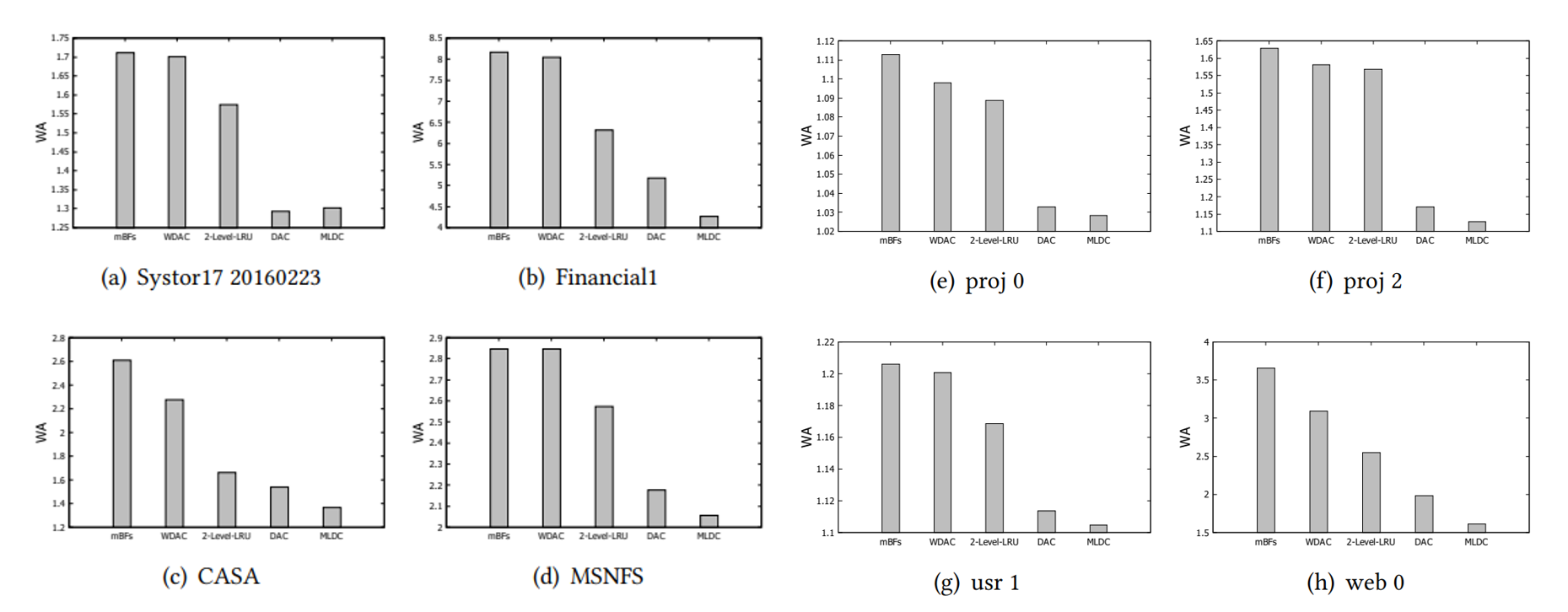
- 성능 비교를 위해 mBFs, WDAC, 2-Level_LRU, DAC, MLDC 총 5가지의 알고리즘에 대한 WA를 비교하였다.
- 그래프에서 보는 바와 같이 본 논문에서 제안한 MLDC알고리즘의 WA가 대부분의 workload에서 가장 낮은 값을 보여주고 있다.