[paper review] Applying Deep Learning to the Cache Replacement Problem
17 Aug 2022
Reading time ~6 minutes
2019 ACM ISBN에 발표된 Applying Deep Learning to the Cache Replacement Problem 논문에 대해 리뷰하겠다. 저자는 Subhash Sethumurugan,Xiangru,Calvin Lin,Akanksha Jain
0. ABSTRACT
해당 논문을 요약하자면 다음과 같다
- 새로운 캐시 교체 정책을 설계하기 위해 딥러닝을 사용
- 딥러닝은 모델이 크고 느려서 hardware predictors에는 잘 쓰이지 않고 있다.
- 오프라인으로 LSTM모델을 사용했을 때 더 좋은 정확도로 에측함을 보여준다.
- LSTM을 분석하여 훨씬 낮은 비용의 온라인 모델을 설계
1. INTRODUCTION

딥러닝이란 다층 신경망을 의미한다. 여러 계층을 사용하기 때문에 비선형 관계를 학습할 수 있는 능력을 제공하여 최근 많은 분야에 적용되고 있다.
하지만 딥러닝은 크기가 크고 학습을 위한 시간이 많이 걸려서 hardware predictors문제에는 적합하지 않다. 따라서 본 논문에서는 Offline에서 LSTM 모델을 설계하여 학습시킨 후 결과를 분석하여 Online 환경에서는 LTSTM의 결과를 바탕으로 비교적 간단한 머신러닝 모델인 SVM 모델을 설계할 것이다.
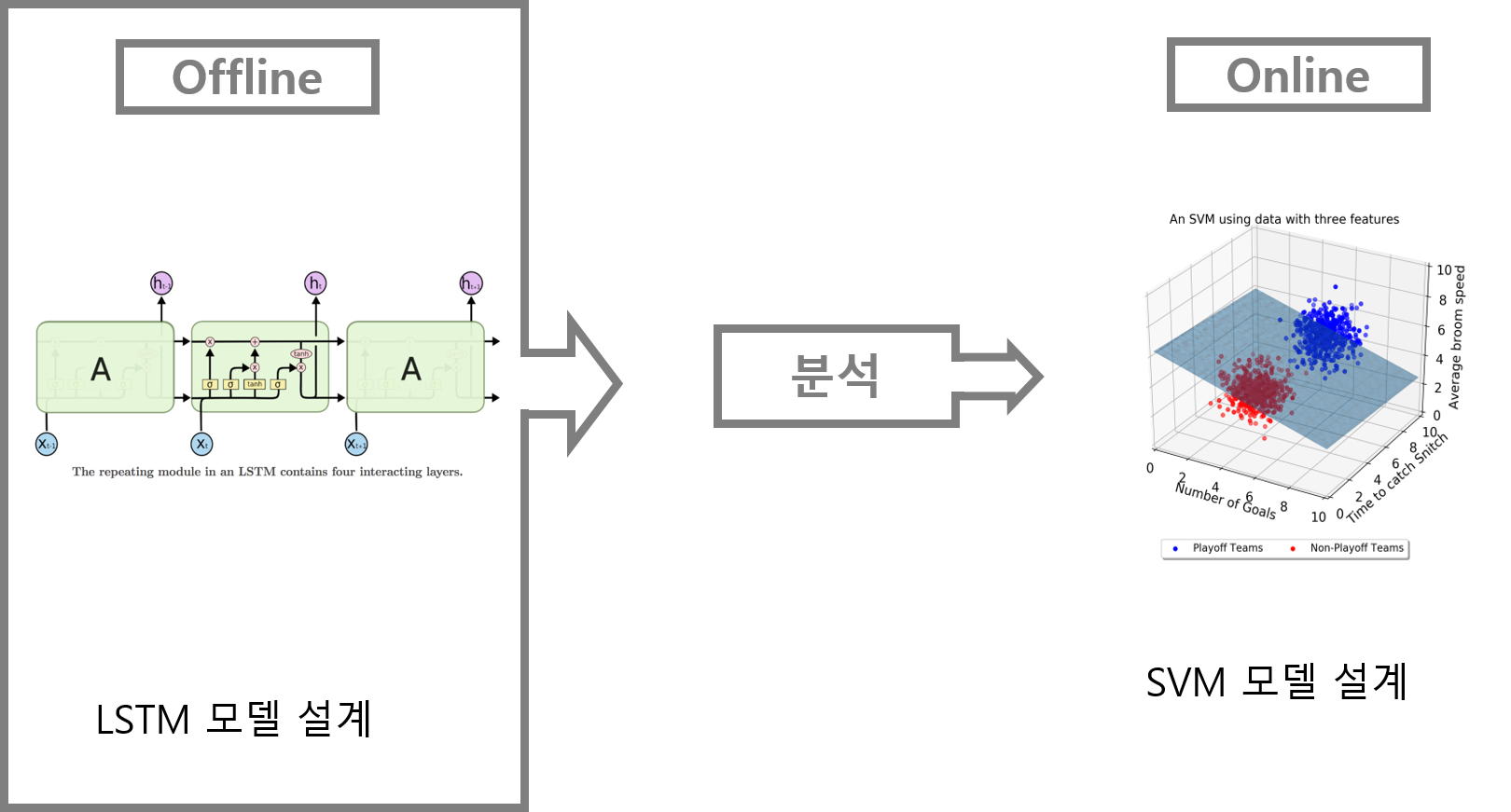
2. BACKGROUND
Hawkeye cache
본 논문에서 설계한 캐시 교체 정책은 Hawkeye Cache를 기반으로 하여 설계하였다. Hawkeye 는 2nd cache replacement Championship에서 우승한 모델로 Glider의 기반이 되는 모델이다.
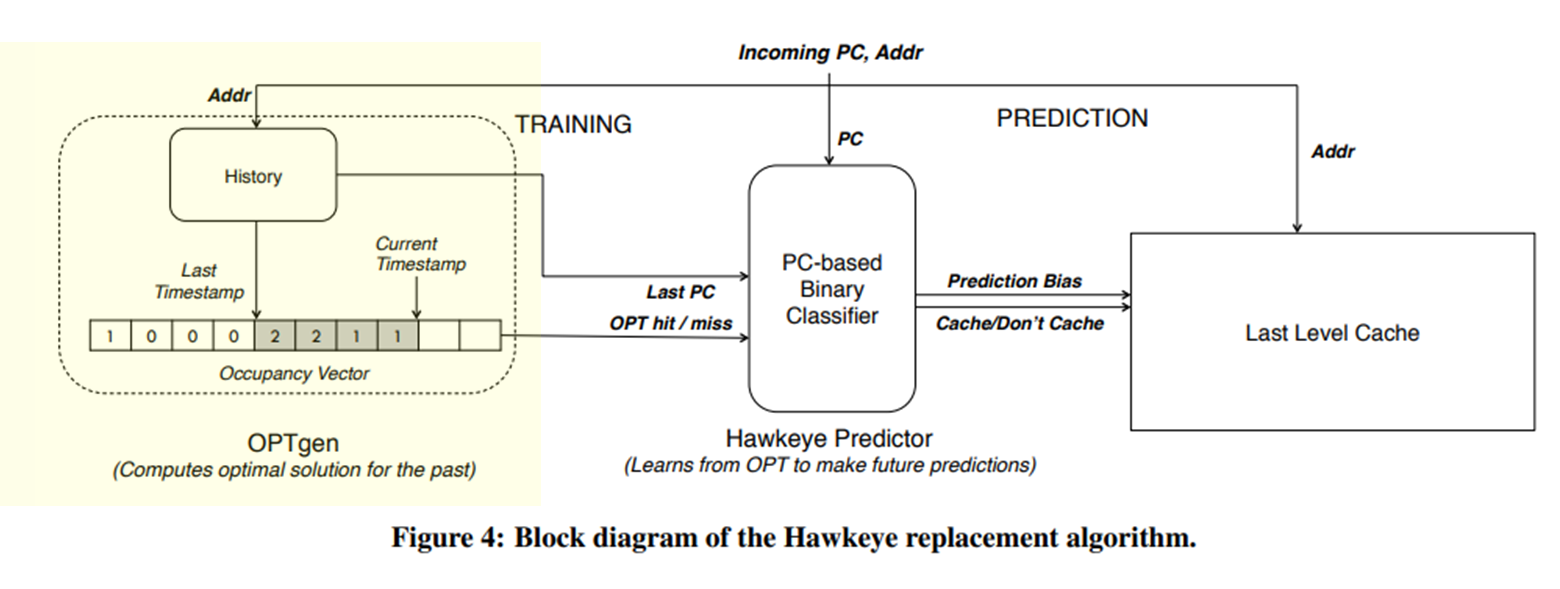
OPTgen에서 현재의 PC에 의해 원래 있었던 PC가 나중에 Hit가 될지 MIss가 될지를 계산한다.
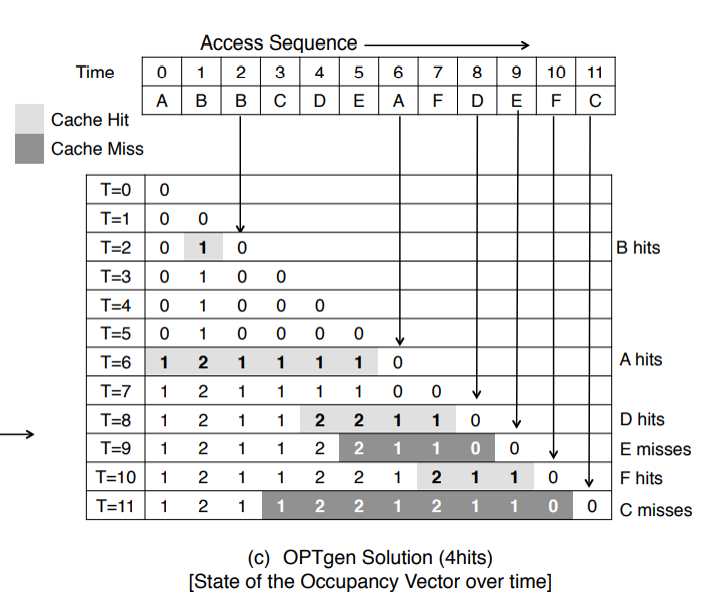
Hit이 되면 재사용 거리만큼을 +1해준다. 그림과 같이 만약 2가 포함되어있으면 해당 데이터는 miss가 된다.
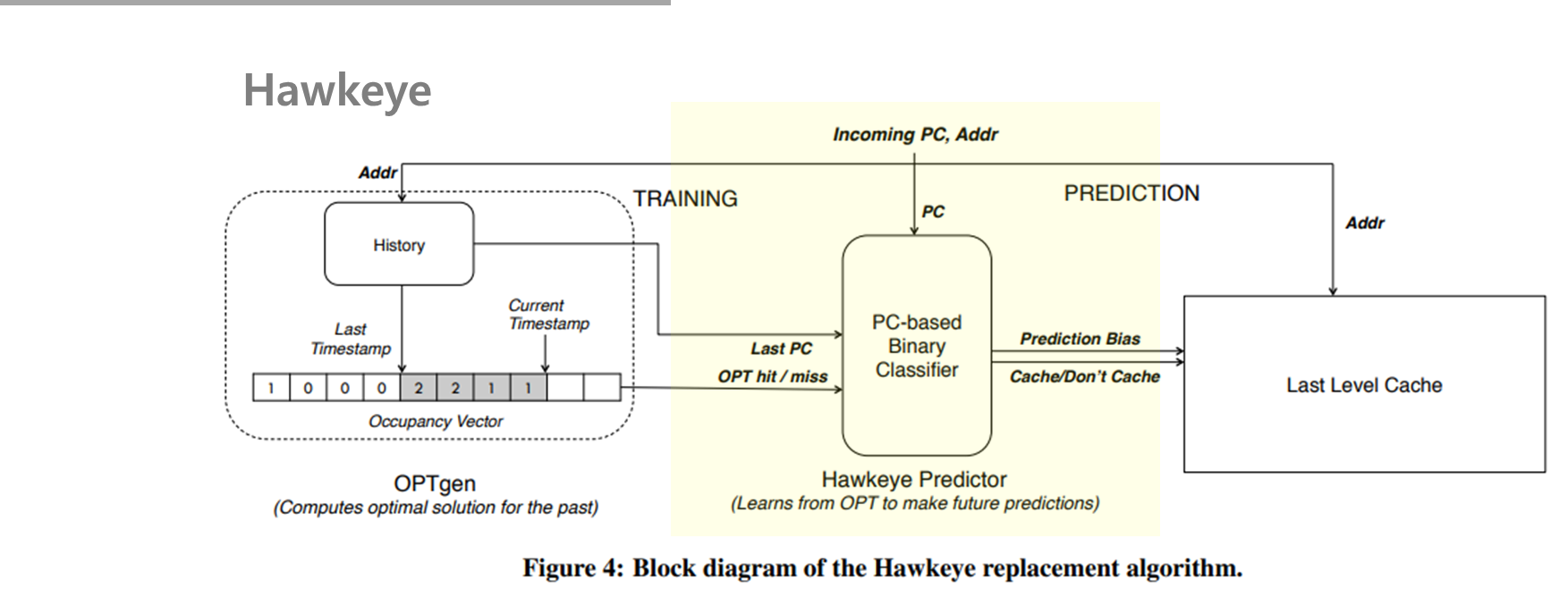
Hawkeye predictor은 PC를 사용하여 주어진 PC에 의한 메모리 access 가 cache-fruendly인지 cache-averse인지를 학습한다.
cache-friendly 데이터는 높은 우선순위로 캐시에 삽입하고,
cache-averse 데이터는 낮은 우선순위로 캐시에 삽입한다.
LSTM
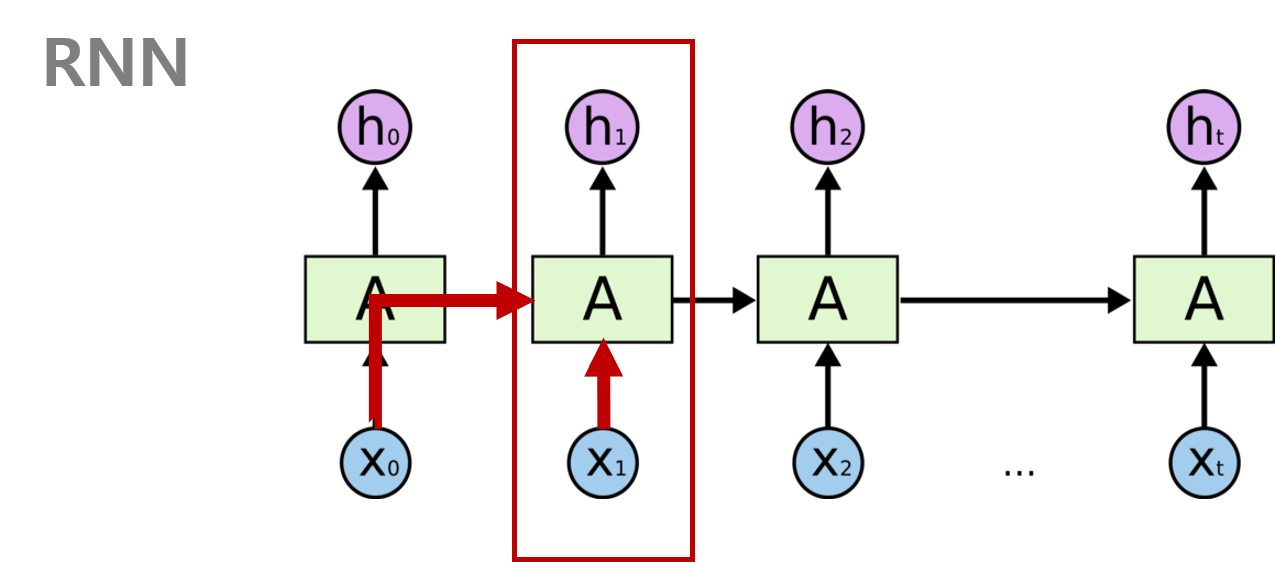
RNN은 이전의 상태와 현재의 입력값에 의해 현재의 상태를 도출하여 예측하는 딥러닝 알고리즘이다.
하지만 RNN은 Vanishing Gradient(기울기 소실) 문제가 발생하는데 이는 길이가 깊어지면 과거의 중요한 정보들이 제대로 반영이 안되어 나타나는 문제이다. 이러한 문제를 보완하기 위해 나온 모델이 LSTM이다.
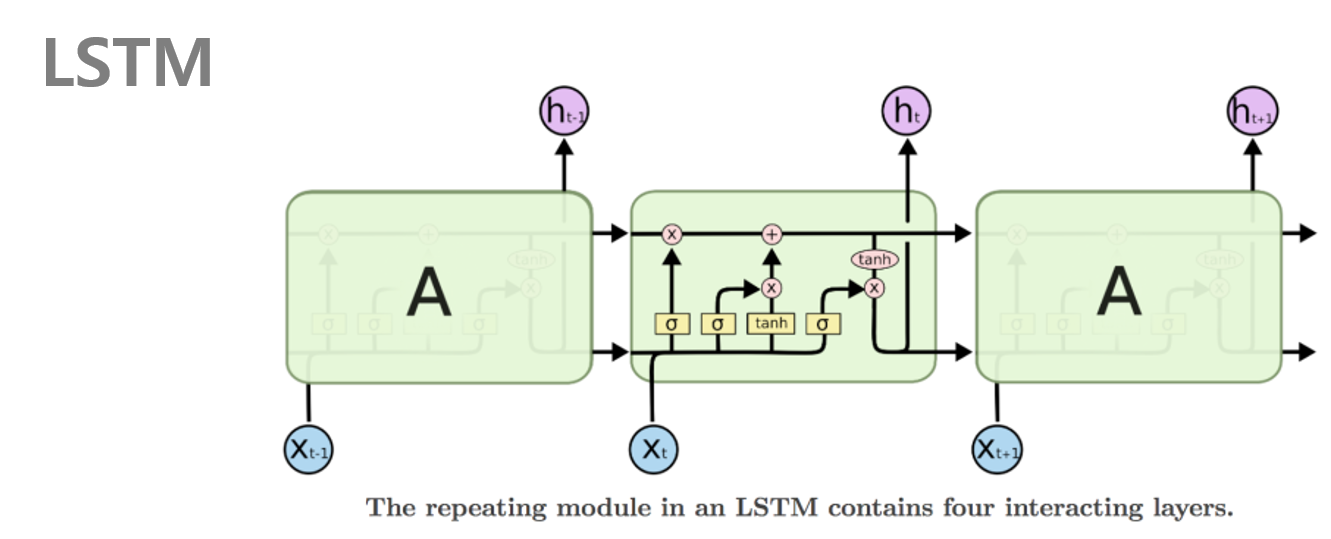
LSTM은 RNN의 문제를 보완하기 위해 기억 할 상태와 기억하지 않을 상태를 gate를 통해 어느정도 조정해준다. 이렇게 되면 중요한 과거 정보와 필요없는 과거 정보를 어느정도 분류하면서 학습을 할 수 있기 떄문에 Vanishind Gradient문제를 어느정도 보완해줄 수 있다.
Attention Mechanisme
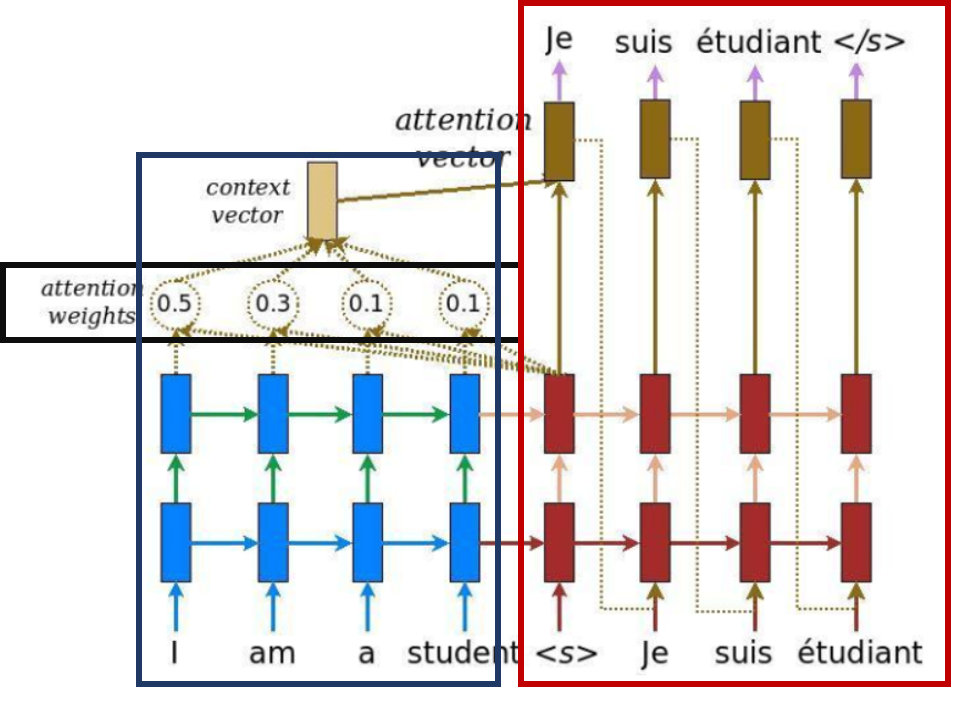
LSTM에 Attention Mechanism을 더해 중요한 정보에 더 집중할 수 있도록 모델을 구성했다.
Attention Mechanism은 그림과 같이 디코더에서 출력 단어를 예측하는 매 시점마다 인코더에서의 전체 입력 문장을 다시 한번 참고하여 attention weights를 정한다. attention weights의 정보를 담은 context vector는 인코더의 예측에 영향을 미친다. 즉 예측할 때마다 전체 문장을 다시 참고함으로써 과거의 데이터를 잊지 않고 중요한 정보에 집중할 수 있게 하는 mechanism이다.
3. OUR SOLUTION
본 논문에서의 연구 방향은 다음과 같다.
- Hawkeye를 기반
- PC가 cache-friendly인지 cache-averse인지 학습하는 것이 목표
- 오프라인 학습에서 LSTM모델을 설계한 후 분석하여 온라인 학습에서 SVM모델을 설계
### load를 식별하는 데 메모리 주소 대신 PC를 사용하는 이유
- PC가 메모리 주소보다 크기가 더 작기 때문에 더 자주 반복하면서 학습 속도를 높일 수 있다.
- 메모리 주소를 나타내는데에는 많은 bit가 사용된다. 따라서 적은 bit로도 메모리 주소를 나타낼 수 있는 PC를 사용한다.
- LSTM 의 size와 학습 시간이 빨라진다.
- LSTM의 학습시간과 크기는 고유한 input에 비례하는데 메모리 주소의 수는 일반적인 LSTM의 입력보다 100~1000배 정도 더 많기 때문에 메모리 주소의 사용이 어렵다.
전체적인 구조

본 논문에서 제시하는 연구의 전체적인 구조이다.
-
Offline
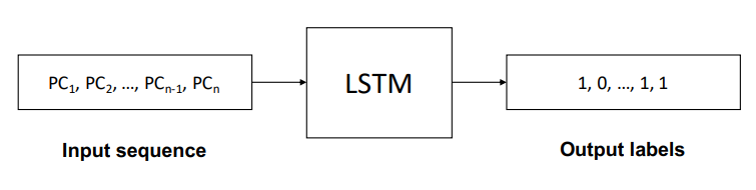
offline 부분에서는 PC를 input sequence로 입력받아 LSTM을 통해 학습을 시키고 해당 PC가 0과 1로 예측한다. (cache-averse인지 cache-friendly인지를 예측한다.)
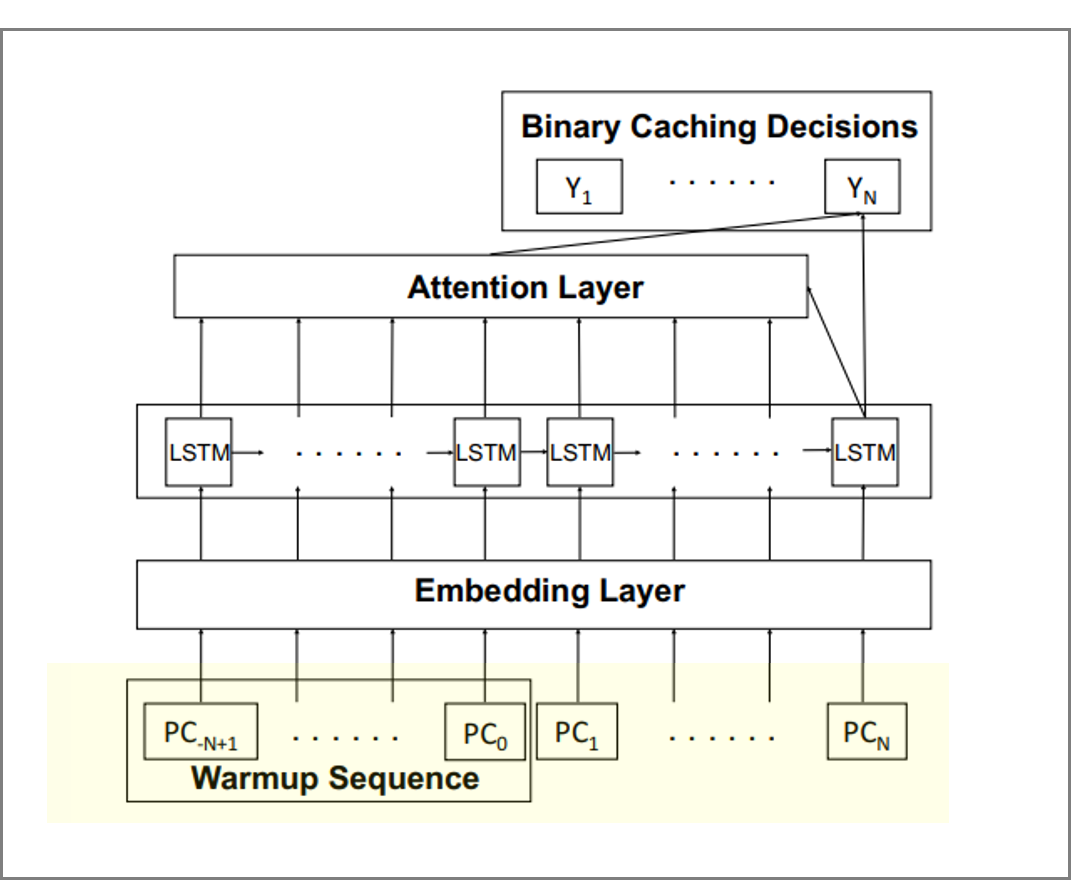
- input sequence
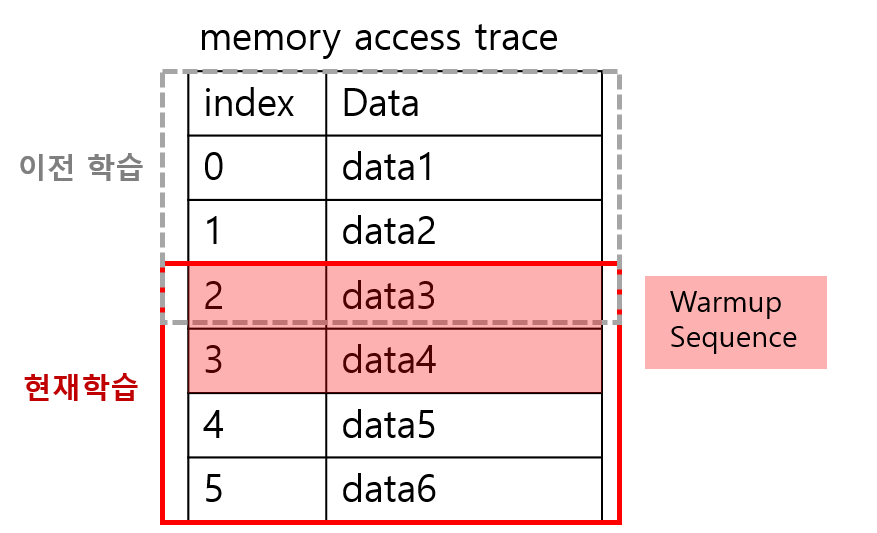
input sequence은 메모리 access trace가 너무 길기 때문에 2N개씩 잘라서 학습을 시킨다. 이때 N개는 이전 시퀀스, N개는 새로운 시퀀스로 자른다. 그리고 각 샘플의 시작에 대해 context 손실을 방지하기 위해서 연속 시퀀스를 시퀀스 길이 N개 만큼 겹쳐서 학습을 한다. 즉 학습을 위한 2N개의 시퀀스에는 이전 시퀀스 N개(warmuo sequence) 새로운 시퀀스 N개가 존재하기 때문에 이전 시퀀스를 다시 학습함으로써 context손실을 방지할 수 있게 되는 것이다.
- Embeding layer
원시데이터를 변환하여 학습 가능한 표현으로 생성하기 위해 embeding layer를 구성하였다.

One-hot 인코딩 같은 경우는 원 데이터에서 벡터로의 변환사이에 아무론 지도나 감독이 없기 때문에 데이터들 사이의 관계를 나타낼 수가 없다. 이러한 문제는 embedding방식으로 개선할 수 있다. embedding은 weight를 형성하여 비슷한 카테고리끼리 더 가깝도록 연결해준다.
-
Attention layer
-
attention layer는 attention mechanism을 이용하여 PC간의 상관관계를 학습시키는 역할을 한다.
-
Binart Caching Decisions
- 예측 결과는 0또는 1의 이진값으로 나타난다.
- 0은 cache-averse를 나타내며 캐시에 친화적이지 않기 때문에 낮은 우선순위의 캐시에 할당한다.
- 1은 cache-friendly를 나타내며 캐시에 친화적이기 때문에 높은 우선순위의 캐시에 할당한다.
-
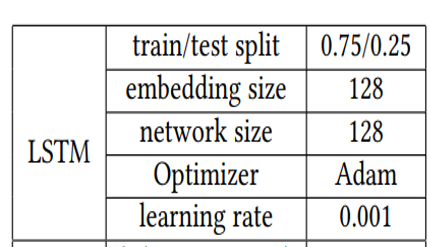
파라미터 설정
- offline에서의 LSTM 모델의 파라미터는 다음과 같이 설정하였다.
-
분석
offline 학습의 분석 결과 캐시 결정은 전체 시퀀스가 아니라 주로 몇가지 메모리 access가 영향을 준다는 사실을 알아내었다. 특히 PC의 history가 10~30때 정확도가 향상되었다. 따라서 결과가 모든 PC가 아닌 몇몇 PC에 영향을 많이 받기 때문에 몇 중요한 PC를 식별하면 된다.
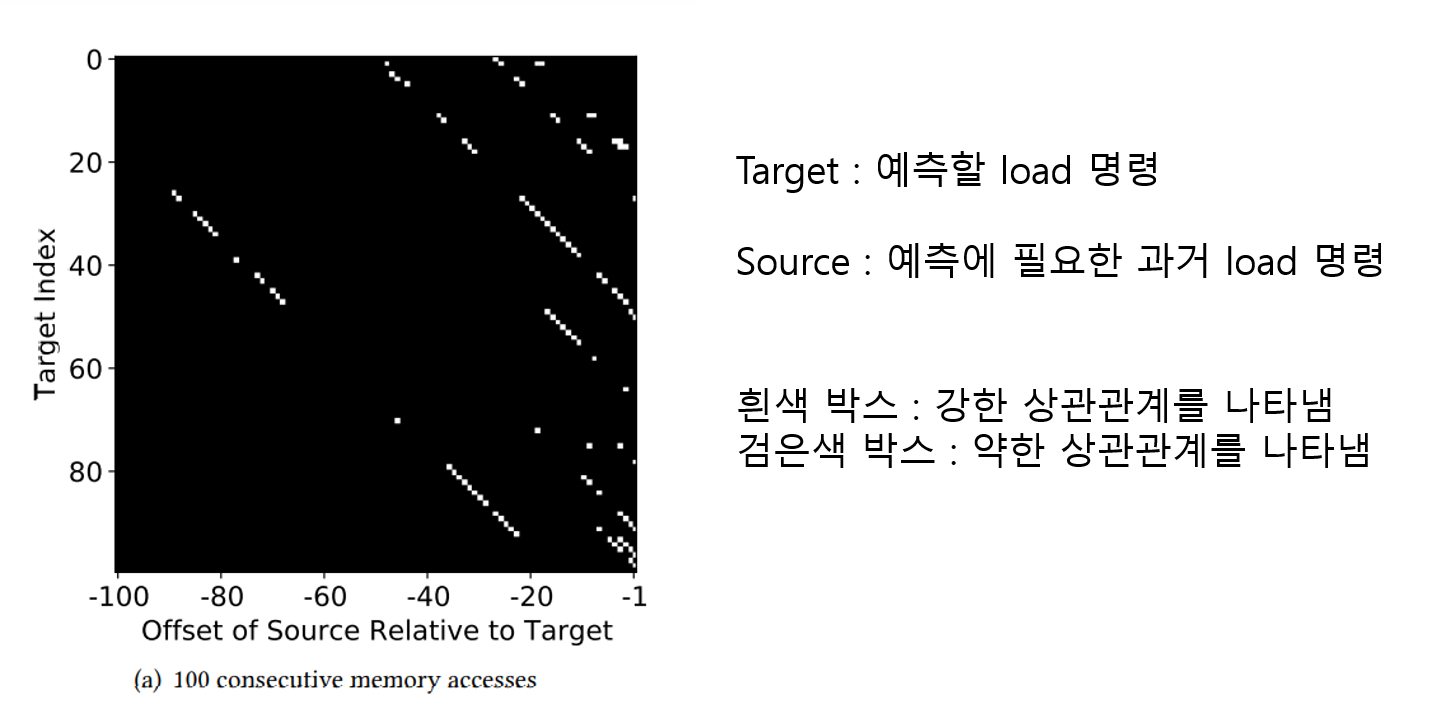
그림은 어떤 load 명령어가 캐시 결정에 영향을 많이 미치는지를 나타내는 그림이다. 그림에서도 알 수 있듯이 캐시 결정에 영향을 끼치는 pc는 전체에 걸쳐서 몇 안되게 나타난다.
-
Online (Glider)
online에서는 앞의 분석을 반영하여 online 학습을 위한 SVM 구현에 대한 부분이다.
- k-spares Binary Feature

offline에서의 학습은 몇몇 PC에 집중하면 된다는 분석 결과를 보여주었다. 이러한 결과를 바탕으로 중복된 PC를 제거, PC History압축, 시퀀스의 순서나 위치를 변경하여도 상관이 없다는 결론을 내어 k-sparse Binary Feature를 제안하였다.

k-spares Binary Feature은 그림과 같이 sequence들을 하나의 벡터로 묶어주며, 효율적으로 feature를 압축시킬 수 있게 된다. 여러 실험을 통해 k의 값은 5로 설정하였다.
- SVM (spport vector machine)
online에서 학습시킬 모델로는 SVM(spport vector machine)을 사용하였다. SVM은 선형 분류 알고리즘으로 두개의 그룹을 분류하는 이진 분류 알고리즘이다. SVM은 ㅇLSTM보다 더 빠르고 가볍기 때문에 공간과 시간의 제약이 있는 online에서의 학습 모델로 적합하다.
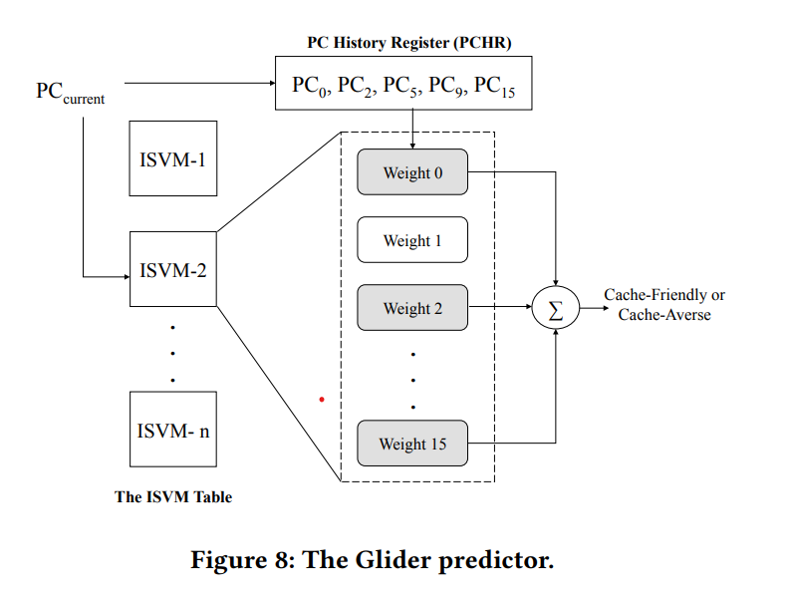
online학습의 전반적인 구조는 위의 그림과 같다. PCHR은 각 코어에서 본 마지막 5개의 PC를 유지, 관리하는 PC History Register이다. ISVM 테이블은 각 PC의 ISVM 가중치 테이블을 의미한다.
- 샘플링 된 세트에 access하면 Glider는 현재 PC 및 PCHR에 해당하는 가중치를 검색한다.
- 예측을 위해 현재 PC에 해당하는 가중치와 PCHR을 합산한다.
- 합계가 임계값보다 크거나 같으면 라인이 캐시 친화적이라고 예측하고 높은 캐시 우선순위로 삽입, 합이 0보다 작으면 라인이 캐시를 싫어할 것이라고 예측하고 낮은 캐시 우선순위로 삽입한다.
4. EVALUATION
Simulator
평가를 위한 Simulator는 Champsim을 기반으로 하는 2nd JILP Cache Replacement Championship에서 발표한 시뮬레이션 프레임워크 사용하였다.
Benchmark
모델을 평가하기 위해 SPEC CPU2006, SPEC CPU2019, GAP의 Benchmark를 사용
- reference input set를 사용하여 Benchmark를 실행하고 CRC2와 마찬가지로 SimPoint를 사용하여 각 Benchmark에 대해 10억개의 명령 샘플을 생성한다.
- 2억개의 명령어에 대해 캐시를 워밍업하고 다음 10억개의 명령어 동작을 측정한다.
Settings for offline Evaluation
- LSTM은 일반적으로 전체 데이터 세트를 통해 여러 번 반복해야하기 때문에 Champsim을 통해 애플리케이션을 실행하여 생성되는 LLC의 액세스 trace로 이러한 모델을 평가
- Belady 알고리즘을 효율적으로 변형시켜 최적의 캐시 결정을 얻을 수 있다.
- 상당한 학습 시간이 필요하기 때문에 2억 5천만 개의 명령에 대해 오프라인 학습 모델을 실행
- 각 trace에 대해 75% 는 학습에 사용하고 25% 를 테스트에 사용
Accuracy eveluation
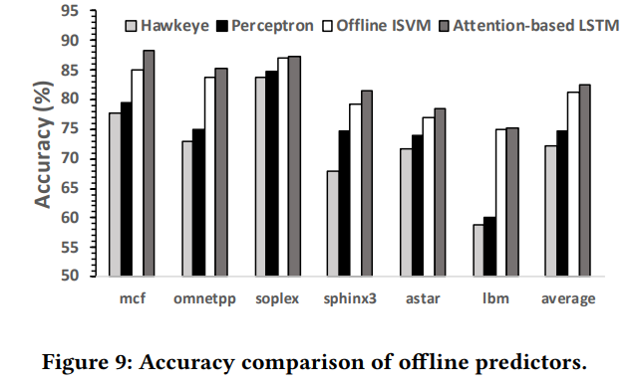
위의 그래프는 offline모델에서 benchmark에 대해 Hawkeye, Perceptron, Offline ISVM, Attention-based LSTM 총 4가지 모델의 정확도를 비교한 그래프이다. offline 모델에서 Hawkeye보다 LSTM이 10.4% 정도 더 높은 정확도를 보여주며, ISVM도 Hawkeye보다 9.1% 더 높은 정확도를 보여준다.
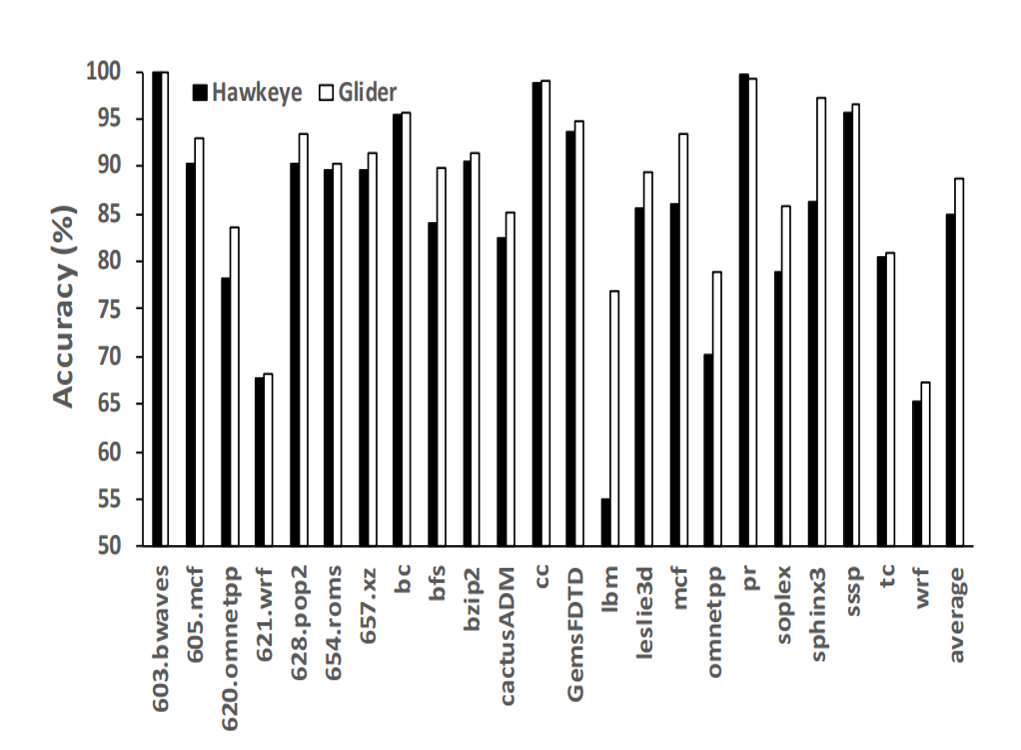
위의 그래프는 online 모델에서 benchmark에 대해 Hawkeye와 본 논문에서 제안한 교체 정책 Glider의 모델 정확도를 비교한 그래프이다. Hawkeye는 평균적으로 84.9%의 정확도 Glider는 평균적으로 88.8%의 정확도를 보여준다.
Miss rate, speed eveluation
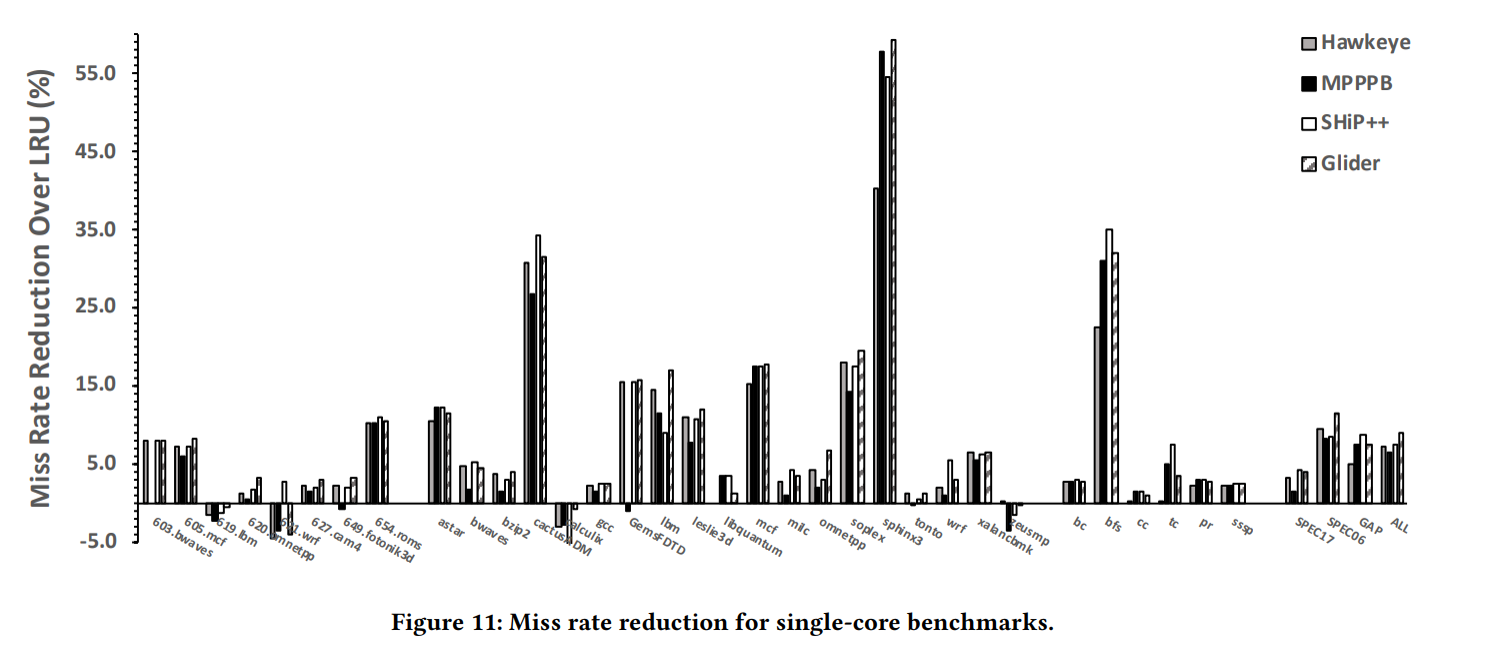
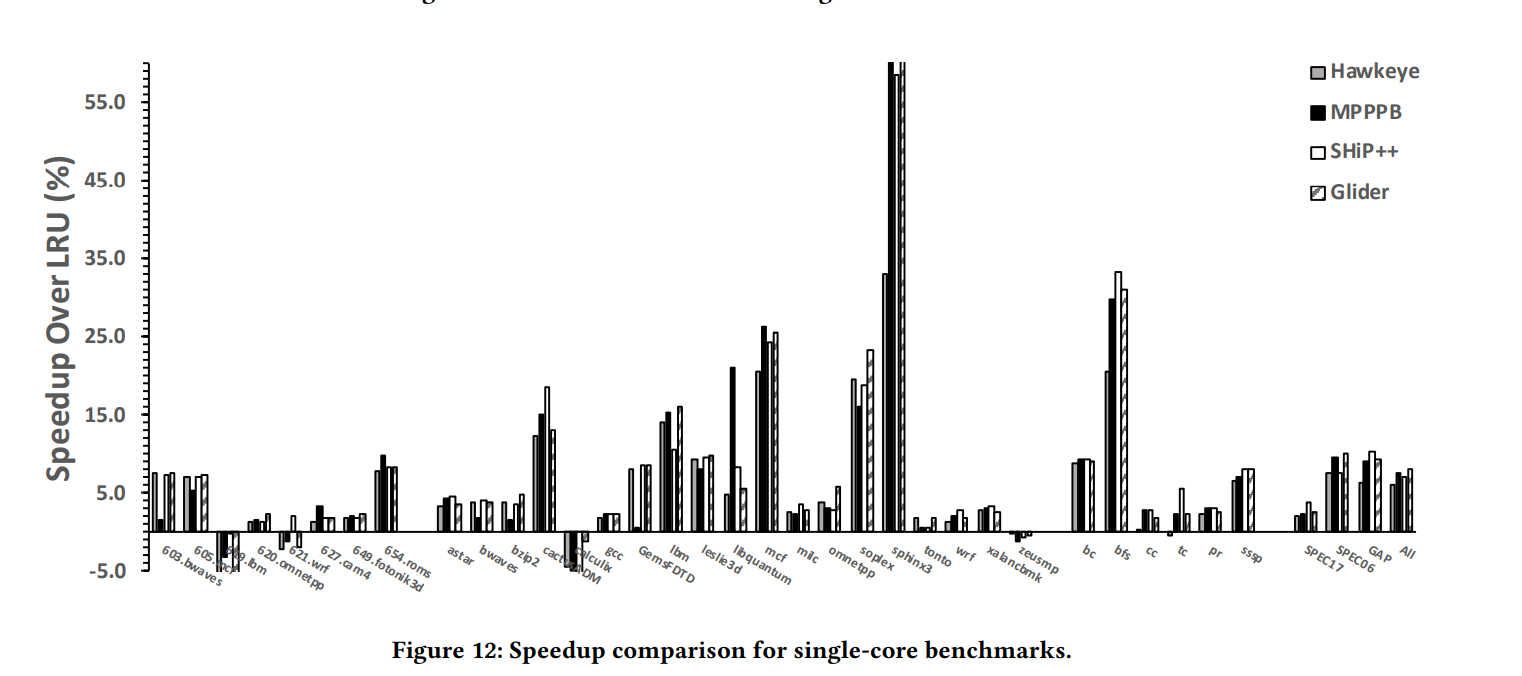
위의 그래프는 single core에서 benchmark에 대해 Hawkeye, MPPPB, SHIP++, Glider 총 4가지 캐시 교체 알고리즘에 대해 LRU대비 miss ratio의 감소된 정도와 LRU대비 속도가 얼마나 향상되었는지를 비교한 그래프이다.
-
miss ratio는 전체 시퀀스에 대해 cache miss된 비율을 나타내며 miss ratio가 크게 나타난다는 것은 캐시 성능이 좋지 않다는 것을 의미한다. 따라서 miss ratio가 낮아질 수록 캐시 성능이 향상된다. 그래프에서 볼 수 있듯이 몇몇 benchmark에서는 다른 교체 알고리즘보다 낮게 나타나지만 전반적으로 Glider의 miss ratio 감소율이 가장 높게 나타난다.
-
속도 또한 몇몇 benchmark를 제외하고는 전반적으로 Glider의 속도 향상 정도가 가장 높게 나타난다.
위의 그림은 총 4개의 모델의 size와 연산 비용을 비교한 그림이다. size와 비용적인 부분에서는 Glider가 다른 모델에 비해 좋은 편은 아니라는 것을 보여주지만, 속도 향상과 miss ratio의 감소만으로도 충분한 의미가 있다.
5. CONCLUSION
본 논문의 결론은 다음과 같다.
- 새로운 캐시 교체 정책을 설계하기 위해 딥러닝 적용 방법을 제시
- 오프라인에서 LSTM 모델 설계
- 오프라인 모델의 결과, 특징 분석
- 분석 결과를 바탕으로 간단한 온라인 모델 설계
- 온라인 모델 기반 새로운 캐시 교체 정책 Glider을 제안