[paper review] Designing a Cost-Effective Cache Replacement Policy using Machine Learning
15 Aug 2022
Reading time ~7 minutes
이번에 리뷰할 논문은 ‘Designing a Cost-Effective Cache Replacement Policy using Machine Learning’. 저자는 Subhash Sethumurugan,Jieming Yin, John Sartori로 HPCA21에 발표된 논문이다.
1 INTRODUCTION
Cache
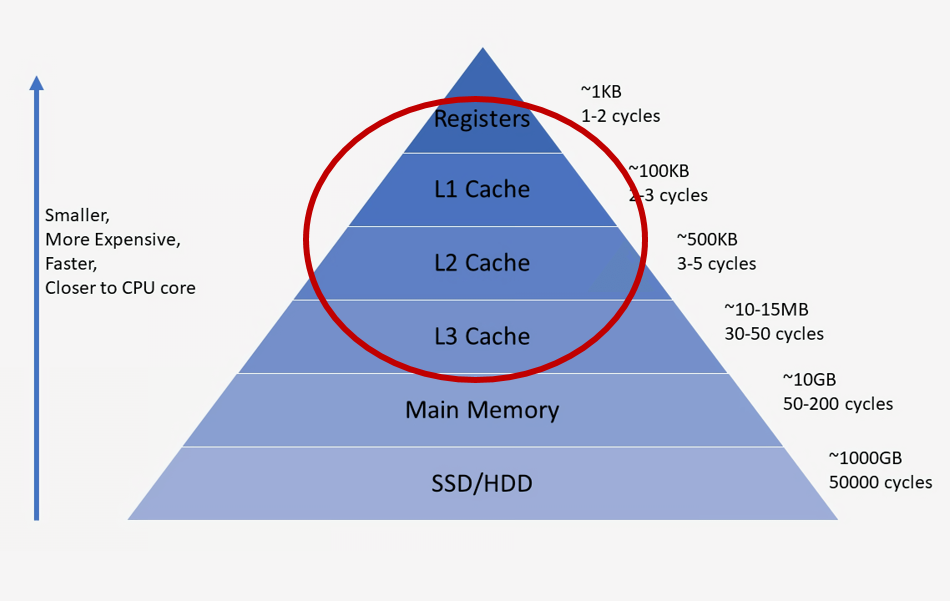
cache란 컴퓨터에서 자주 쓰는 데이터나 값을 미리 복사해 놓는 임시 장소로 프로세서와 메인메모리의 시간적, 공간적 차이 때문에 사용한다.
쉽게 말해서 컴퓨터가 명령어를 처리하기 위해 메인메모리에 저장되어있는 데이터를 읽어와야 하는데, CPU에서 메인메모리로 데이터를 읽어오기 위해서는 시간이 오래 걸리게된다. 하지만 CPU 에 캐시 메모리를 두어 자주 사용하는 데이터를 저장 시켜 놓으면 데이터를 읽어오기 위해 메인 메모리까지 데이터를 읽어올 필요가 없기 때문에 성능이 훨씬 향상된다.
cache는 CPU뿐만 아니라 HDD, ODD등 시간적 공간적 차이가 있는 두 게층 사이에 존재할 수 있다.
- L1 cache : CPU가 가장 빠르게 접근하는 캐시
- L2 cache : L1에서 데이터를 찾지 못하면 접근해서 데이터가 있는지 확인
- L3 cache (= LLC cache): L2에서 데이터를 찾지 못하면 접근해서 데이터가 있는지 확인
cache struct
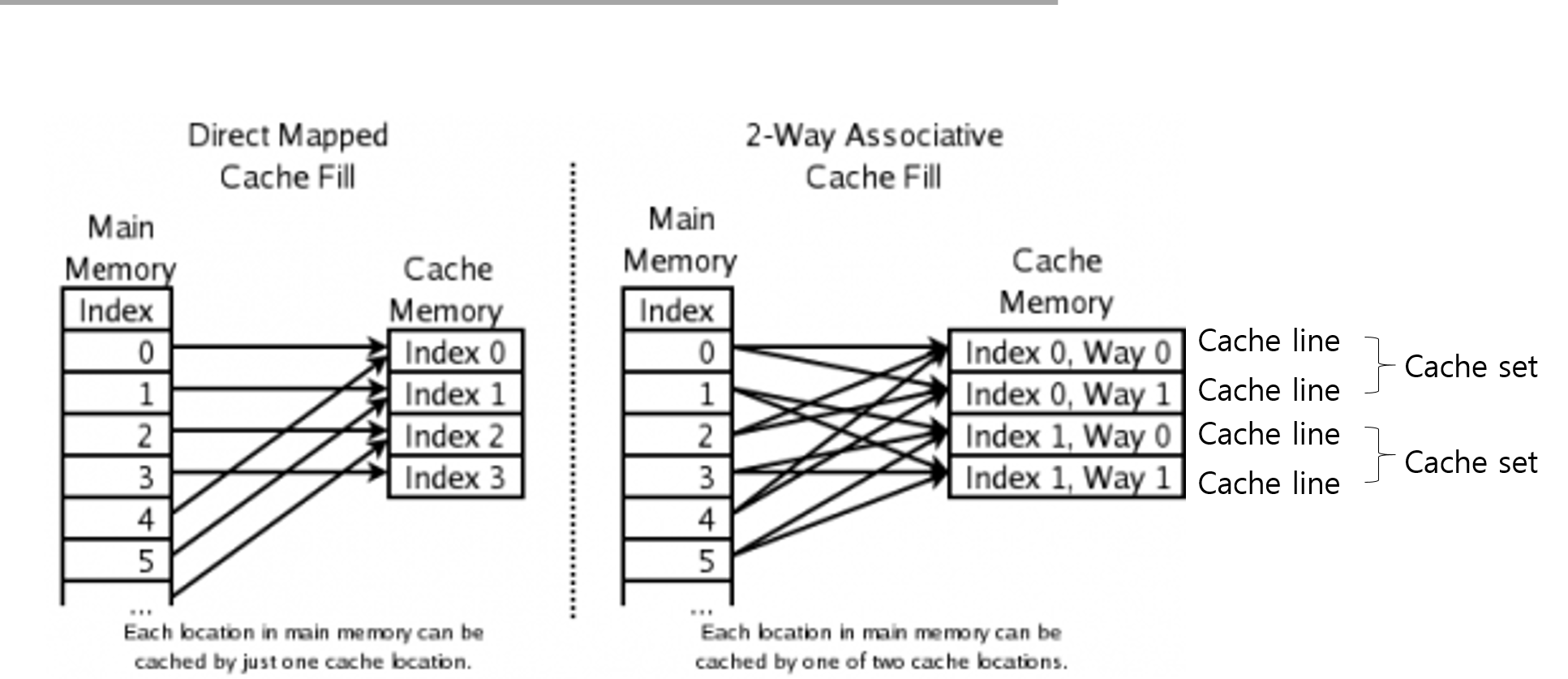
캐시는 Direct Mapped Cache와 n-way Associative cache로 나눌 수 있다.
-
Direct Mapped Cache : 메인메모리의 각각의 주소가 캐시 메모리의 한 위치에만 매핑될 수 있는 캐시 구조
-
n-way Associative cache : 메인메모리의 각각의 주소가 캐시 메모리의 N개의 위치에 매핑될 수 있는 캐시 구조
- cache Line : 하나의 cache set에서의 각각의 캐시 메모리 라인
- cache set : n개의 cache line을 하나의 집합으로 나타낸 단위
cache replacement
캐시 메모리는 빠르지만 공간이 매우 제한적이고 유한하기 때문에 효율적으로 사용하기 위해서는 어떤 정보를 오래 저장할 것인지를 결정해야한다. 어떤 정보를 오랫동안 저장할지를 결정 하는 정책을 캐시 교체 정책이라고 한다.
-
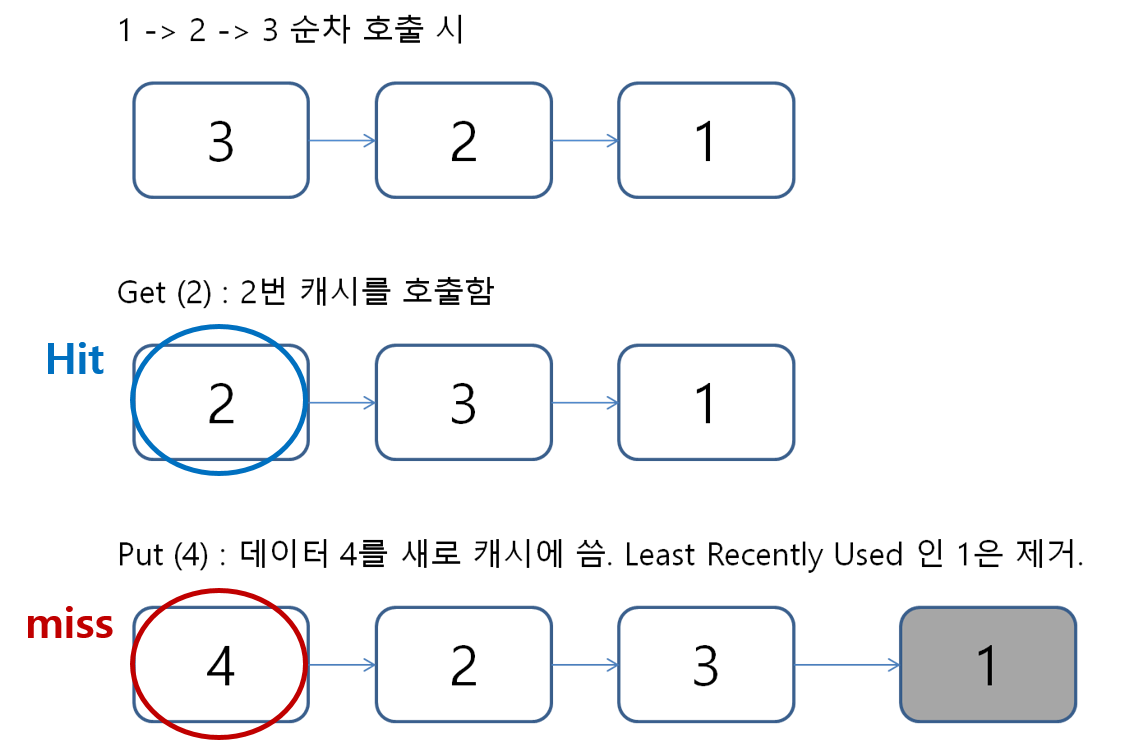
LRU(Least-Recently used):
가장 대표적인 캐시 교체 정책으로 가장 오랫동안 사용하지 않은 페이지를 교체한다.
-
PC(preogram counter)기반의 캐시 교체 정책:
아래 그림에서 노란색으로 표시된 캐시 교체 정책들은 PC기반의 캐시 교체 정책으로 오버헤드가 대체로 크다.
PC를 교체 정책에 통합은 위해서는 PC저장을 위해 캐시 구조를 수정, PC에 대한 추가적인 저장 오버헤드 발생, LLC에서 PC에 접근하기 위한 데이터 경로 수정을 하기 때문에 오버헤드가 대체로 크게 나타난다.본 연구에서는 캐시 교체 정책에 PC를 통합하였을 때와 비슷한 성능을 내면서 오버헤드는 줄일 수 있도록 강화학습 이용한 캐시 교체 정책인 RLR(Reinforcement Learned Relpacement) 알고리즘을 고안하였다.
2 MACHINE LEARNING-AIDED ARCHITECTURE EXPLORATION
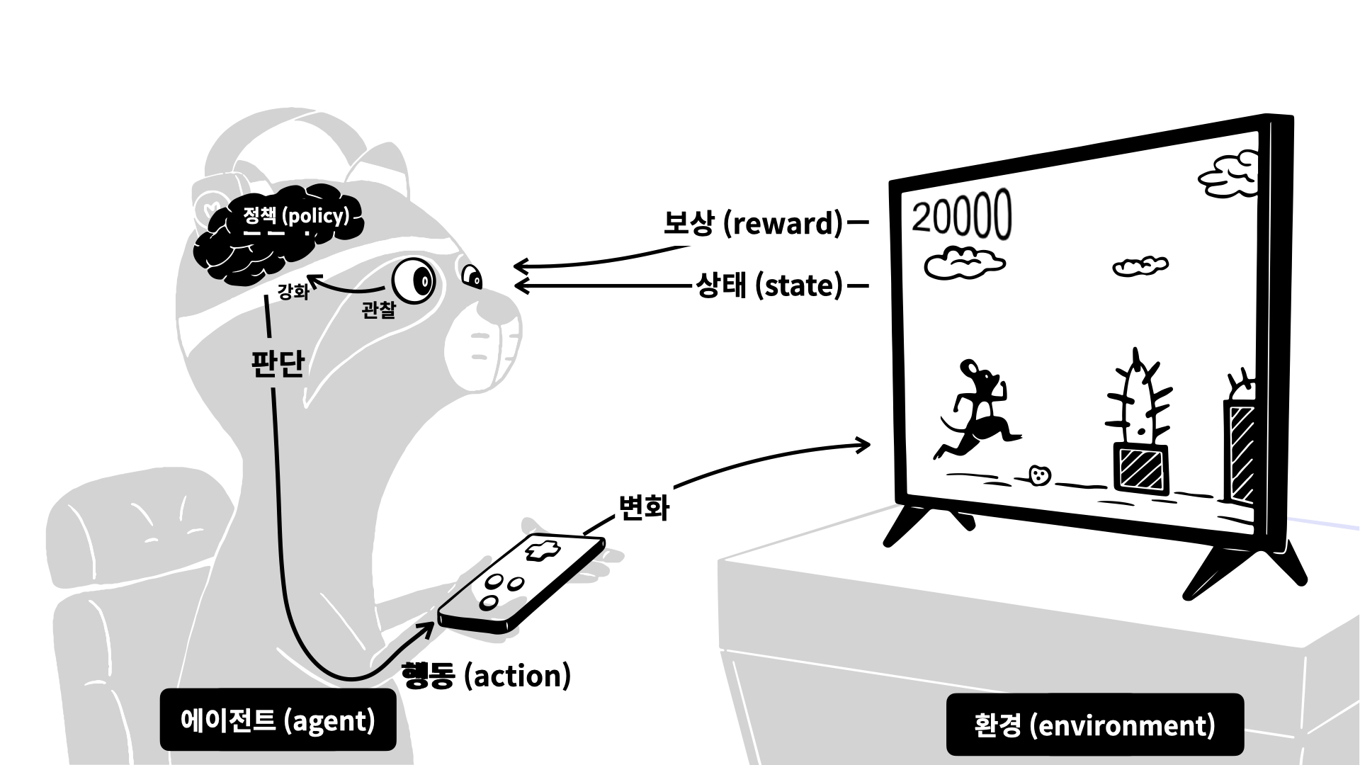
강화학습
강화학습.
머신러닝과 딥러닝은 배움을 통해서 학습을 하는 반면 강화학습은 경험을 총해 학습을 하는 인공지능이다.
행동을 하고, 행동에 대한 결과를 판단하는 주체를 에이전트(agent)라고 하고, 행동에 대한 결과과 좋은지를 안 좋은지를 나타내는 척도가 보상(reward)이다.
에이전트는 행동의 결과가 자신에게 유리한 것이라면 많은 보상을 받고 불리한 것이라면 보상을 적게 받는다. 이러한 과정을 매우 많이 반복하여 더 많은 보상을 받을 수 있는 더 좋은 답을 찾아내는 과정으로 학습을 시켜 더 좋은 행동을 할 수 있도록 하는것이 강화학습의 기본 아이디어이다.
강화학습은 동적변화에 잘 적응하기 때문에 캐시교체 문제에 적합하며, 본 논문에서는 에이전트가 캐시 교체를 결정하는 방식으로 강화학습을 사용한다.
#### RLR 구조
본 논문에서는 캐시 교체 정책을 학습하기 위해 RL(Reinforecement Learning)알고리즘을 사용하여 신경망을 학습시킨다. 학습된 신경망이 효율적일 수는 있지만 하드웨어에 신경망을 구축하는 것은 공간 제약 때문에 비효율적이라 판단하여 학습된 신경망에서 얻은 통찰응 사용하여 하드웨어에서 구현할 수 있는 교체 알고리즘을 도출하였다.
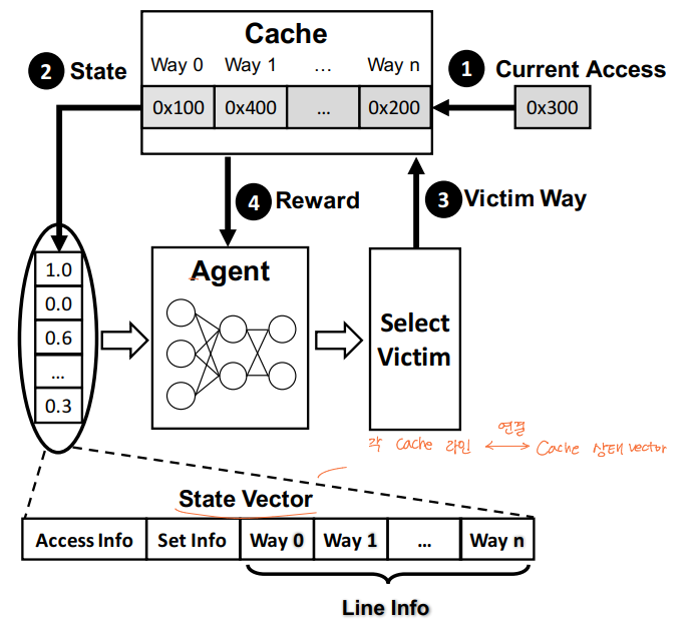
- 기존에 있던 LLC 캐시 공간에 새로운 데이터가 들어오게 되면 각 캐시 라인은 state vector로 연결시킨다.
- 기존의 캐시 상태를 에이전트에게 보낸다.
- 에이전트는 교체할 페이지를 결정한다.
- 에이전트에게 결정의 결과에 따른 보상을 준다.
캐시가 hit 된 경우
- 캐시 상태를 업데이트 하여 Hit 된 access의 counter를 증가
- 다음 access로 넘어감
캐시가 miss 된 경우
- 캐시의 상태를 나타내는 state vector를 에이전트에게 전송
- 에이전트가 교체할 페이지를 결정
- Miss인 access의 counter를 0으로 설정
input vector
캐시의 현재 상태에 대한 정보와 miss된 access의 정보가 합쳐진 state vector가 에이전트에게 전송된다.
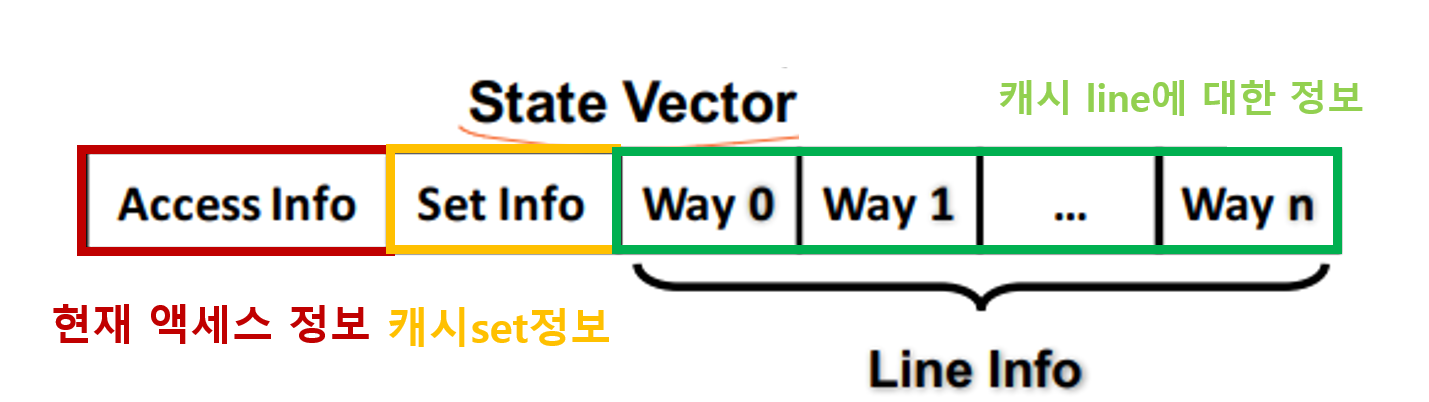
- Access Info : 현재 access 정보
- Set Info : 캐시 Set의 정보
- way0~wayn : 캐시 Line의 정보
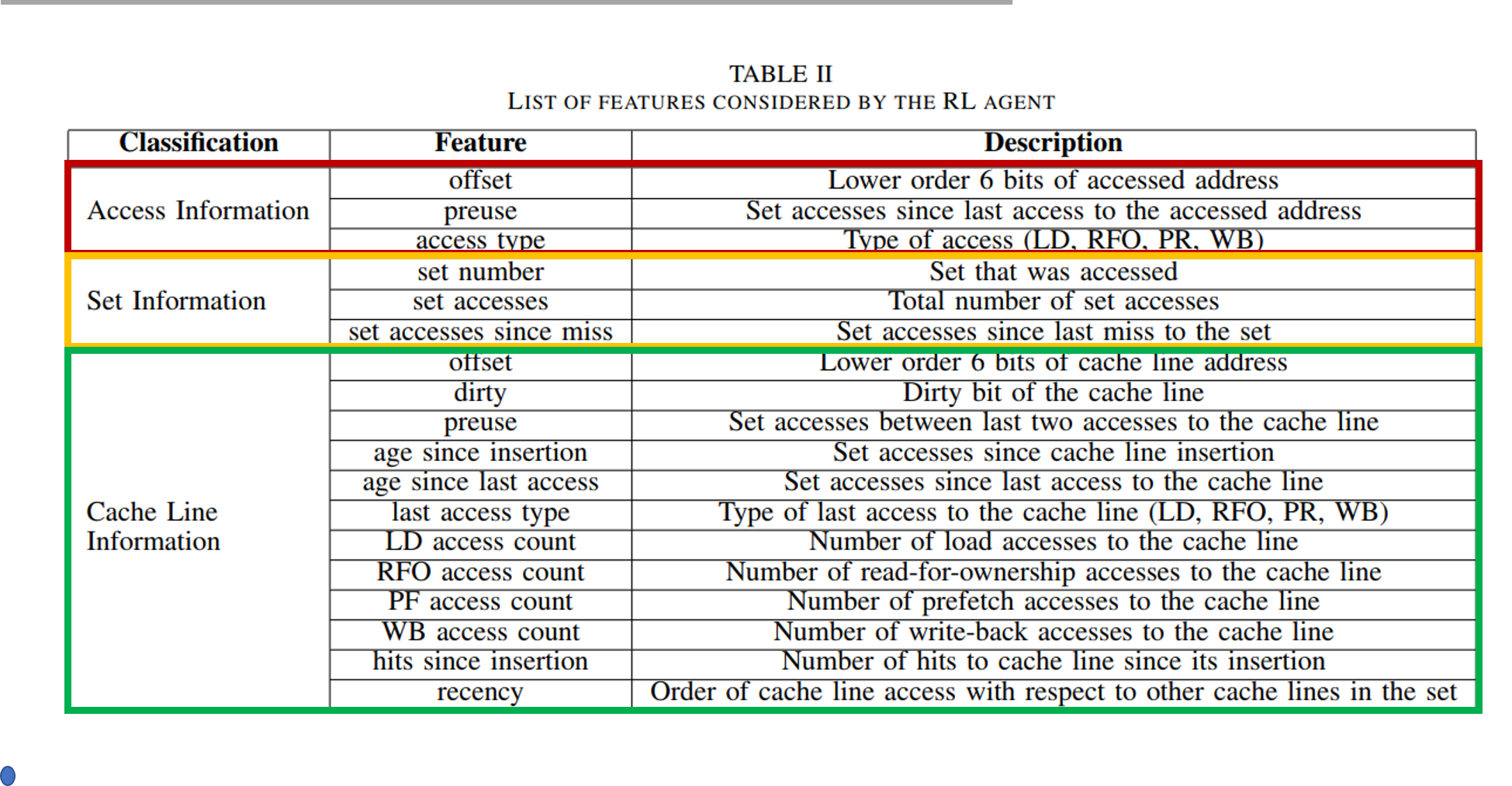
구체적인 정보는 아래의 표와 같다.
에이전트
다층 퍼셉트론으로 활성화 함수는 hidden layer에 tanh, output layer에 linear 함수를 사용하였다.
output vector
출력 벡터의 각 요소는 캐시 집합에서의 way에 해당한다. 이 값은 교체를 위해 특정한 페이지를 선택했을 때 얼마나 좋은 보상을 낼 수 있는지를 나타낸다.
교체 결정
출력 벡터에 기초하여 교체 결정을 내린다. 보상이 얼마나 되는지에 대한 수치가 생성되고 추가적인 교육을 위해 에이전트에게 보내진다. 캐시 교체 정책은 자주 사용하지 않는 즉, 자주 hit 되지 않는 access를 교체 해야 좋은 성능을 낼 수 있으므로 자주 hit 되는 access를 교체 대상으로 선정했을 때 보상은 음수값(-)이 되고 자주 hit 되지 않는 access를 교체 대상으로 선정했을 때 보상은 양수값(+)이 된다.
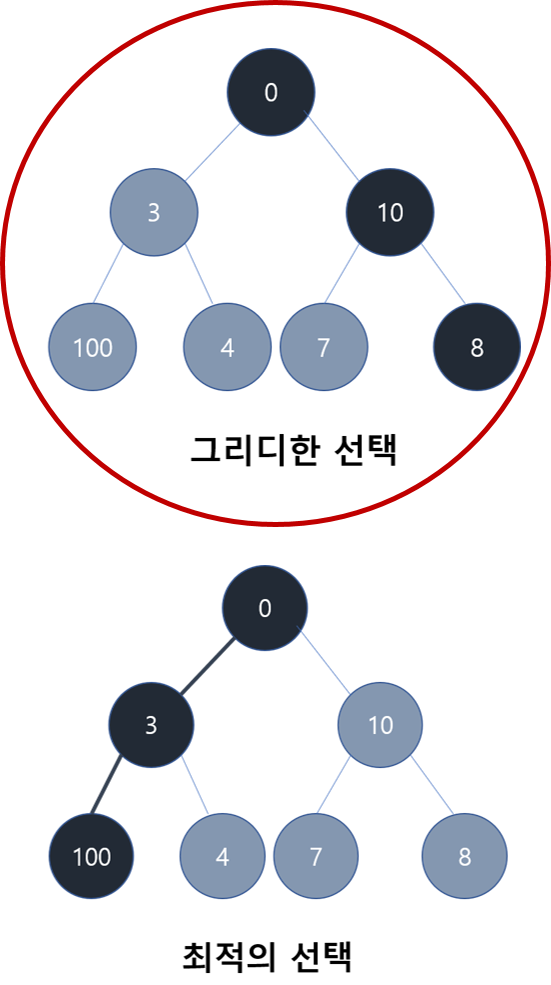
교체할 페이지를 선택하기 위해서 greedy 알고리즘을 사용한다. greedy 알고리즘은 전체적으로 최적의 선택을 계산하는 것이 아니라 지역적으로 가장 최선의 선택을 하는 알고리즘이다.
강화학습은 경험을 통해 학습을 하기 때문에 계속해서 새로운 환경을 접해봐야 여러 경험을 하면서 최적의 행동을 학습해야한다. 따라서 본 논문에서는 0.9의 확률로 보상이 최대인 페이지를 선택하되, 0.1의 확률은 무작위로 선택하게 하여 새로운 궤적을 탁색하고 검색 공간을 확장할 수 있도록 하였다.
3 MACHINE LEARNING-AIDED ARCHITECTURE EXPLORATION
Experience replay
에이전트 학습을 위해 experinence replay 기술을 사용한다.
experince replay 란 에이전트가 과거의 경험을 기억해서 학습에 재사용할 수 있게 하는 방식이다.
기존에는 새로운 데이터가 들어오면 에이전트는 데이터를 학습하여 파라미터를 업데이트 하는데 이렇게 한번 쓴 데이터는 다시 사용되지 않고 다시 새로 들어온 데이터에 대해서만 파라미터를 업데이트 한다. 그래서 데이터들의 전체적인 분포나 특성을 잊기 때문에 전체적으로 최적의 결과에 수렴하는것이 아니라 지역적으로 최적의 결과에 수렴하게 되는 문제점이 있다.
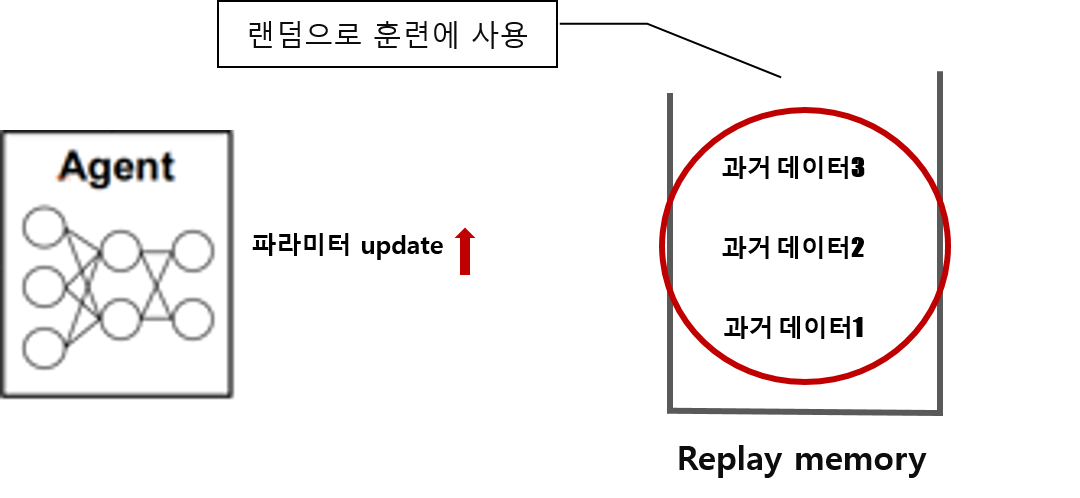
Experince replay는 이러한 문제를 보완하고자 과거에 사용했던 데이터들을 replay memory에 저장하여 학습을 할 때 저장했던 데이터들을 무작위로 샘플링하여 훈련에 사용하는 기술이다. 랜덤으로 데이터를 학습하게 되면서 고르게 분포된 데이터로 학습이 가능하기 때문에 지역적인 문제를 보완할 수 있다.
Neral network 분석
앞서 언근했던 바와 같이 본 논문에서는 하드웨어에 신경망을 바로 적용하는 것이 아니라 학습된 신경망을 분석하여 하드웨어에 적합한 알고리즘을 구현하여 적용할 것이다.
학습된 신경망의 분석을 위해 Heat map과 hill-climbing 분석을 사용하여 feature 별로 중요도를 확인하고 feature의 특성을 분석하였다.
-
Heat map
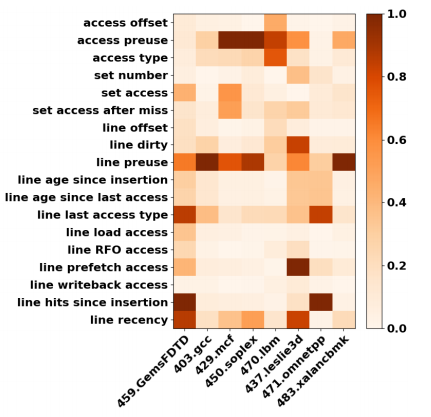
- 변수와 변수 사이의 선형적 관계가 있는지를 계산하여 관계성을 나타낸다.
- 일반적으로 더 높은 가중치를 가진 특징이 더 중요하다. (맵에서 어두울수록 중요도가 높음)
- Heat map을 통해 feature의 중요도를 분석한 결과 1.access preuse, 2.line preuse, 3.line last access type, 4.line recency 특징이 중요하게 나타났다.
-
hill-climbing analysis
- 현재 상황에서 더 올라갈 곳이 있는지 확인 해보고 더 올라갈 곳이 있으면 이동, 없으면 그곳을 peak(꼭대기)라고 간주
- greedy와 같은 계열의 알고리즘이다.
- Feature 쌍의 경우의 수가 많을 대 계산의 부하를 줄이고 시간을 단축할 수 있다는 장점이 있다.
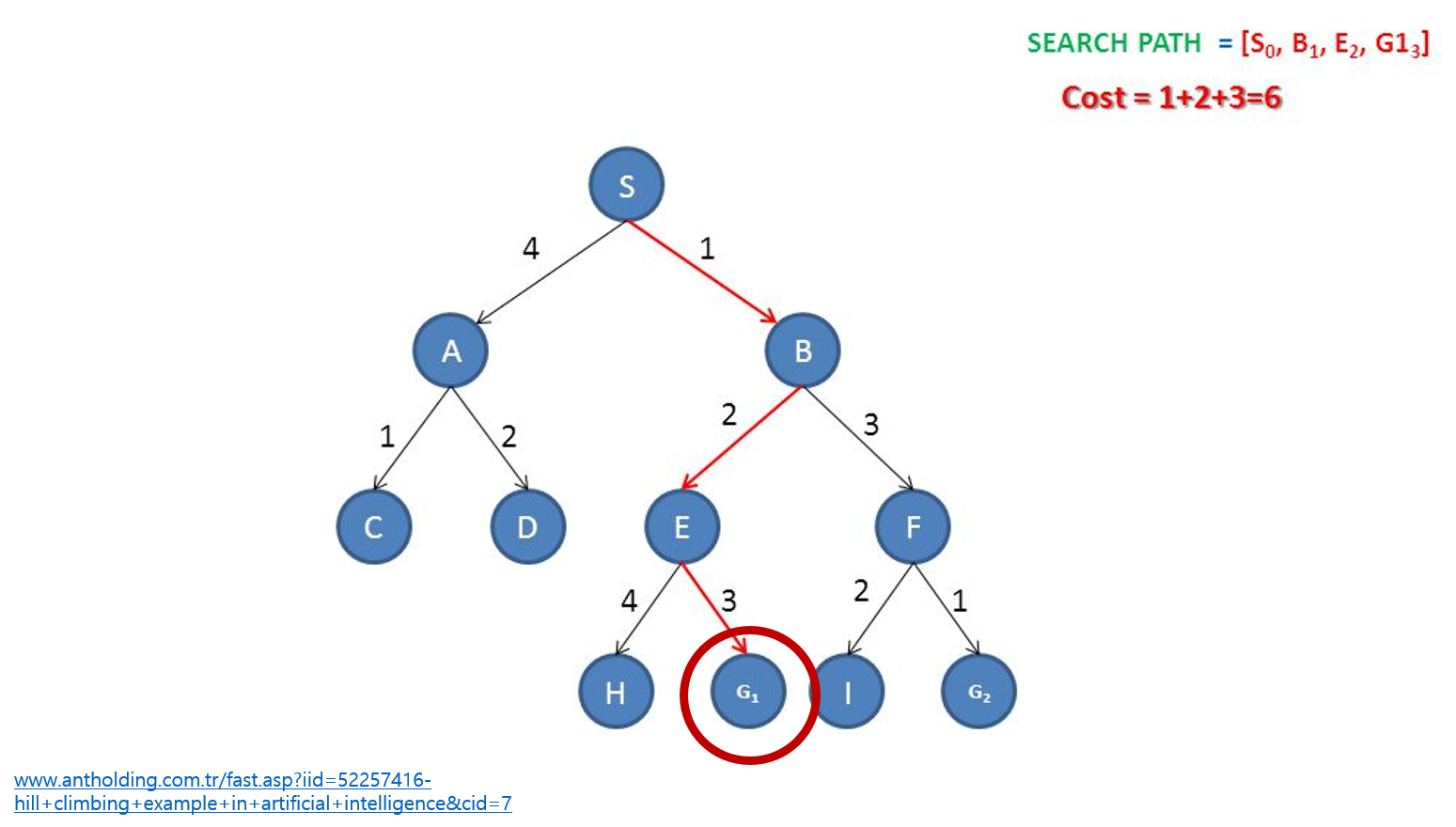
- 각각의 feature에 대해 hill-climbing analysis를 사용하여 성능이 가장 좋아지는 특징 쌍을 확인
-
- Acess preuse distance, 2. Line preuse distance, 3. Line last access type, 4. Line hits Since Insertion 5. Recency 의 특징쌍이 성능이 가장 좋아지는 특징 쌍으로 확인되었다.
preuse distance
- 캐시 라인의 이전 reuse distance
- 캐시 라인의 현재 access와 마지막 access 사이의 set access의 개수로 계산
Line last access type
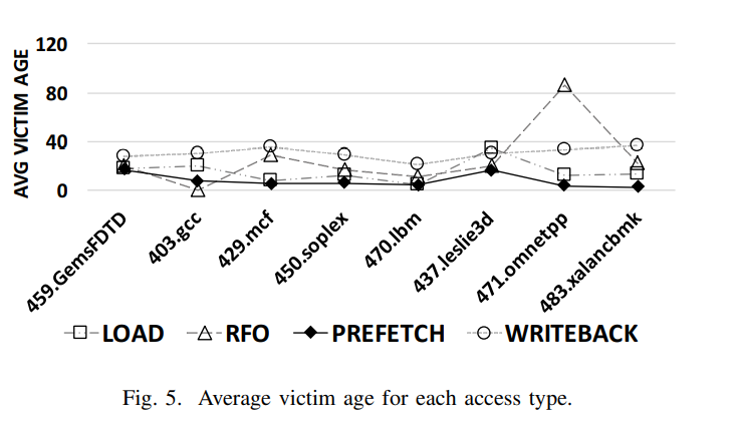
- 마지막 access의 access 타입
- Access type에 따라 재사용이 자주 되는 cache line인지를 확인
- 그래프에서 보는바와 같이 type이 prefetch access인 경우에는 victim 수명이 짧다 따라서 자주 재사용 되지 않는 prefetch 캐시 line을 더 빨리 제거하는 것이 좋다.
Line hits since insertion

- 캐시 라인이 삽입된 이후 Hit 한 횟수
- Hit 한 횟수가 작을 수록 Victim 이 될 가능성이 많다.
Recency
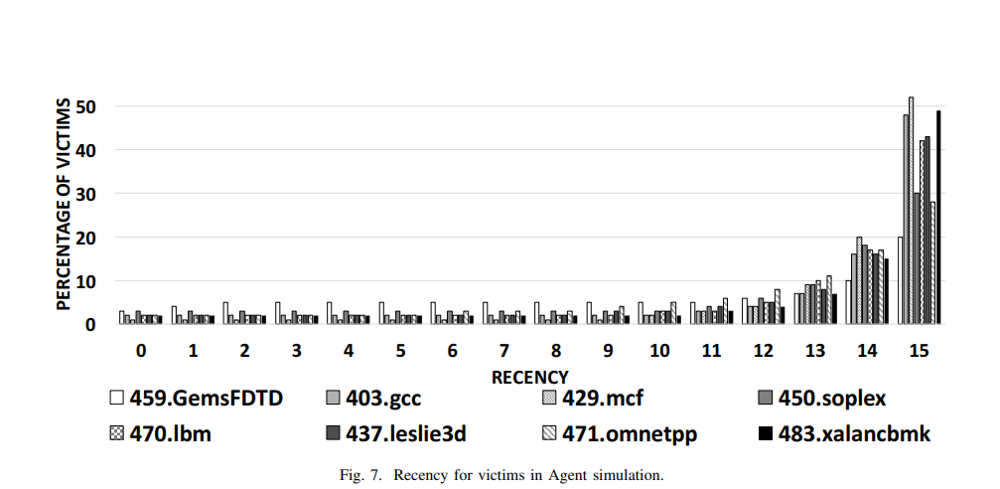
- Set의 cache line의 상대적인 access 순서, 즉 얼마나 오랫동안 캐시 메모리에 저장되어있었는지를 나타내는 지표
- 범위는 0 ~ (set의 line 개수 - 1)
- Recency 값이 높을수록 최근에 access된 캐시 라인이기 때문에 재사용 될 가능성이 낮아 victim 이 될 확률이 높아진다.
- Reuse distance가 같은 경우에는 recency값이 더 큰 캐시라인을 제거한다.
4 Reinforcement learned replacement(RLR)
RLR을 통해 학습된 결과에 대한 분석을 바탕으로 실제 하드웨어에 적용할 수 있는 대체 알고리즘을 설계하였다.
앞서 특징들의 중요도와 결과에 미치는 영향들을 분석하였을 때 총 4가지 분석 결과를 바탕으로 캐시 line에 우선순위를 부여하여 우선순위가 낮은 캐시 line을 교체 대상으로 선정하도록 알고리즘을 설계할것이다.
- Reuse distance는 Preuse distance를 기준으로 예측한다.
- 캐시 라인의 이전 access type을 사용하여 hit 가능성을 예측한다.
- Rececny정보를 활용하여 최근에 삽입된 캐시 line에게 제거 우선순위를 부여한다.
-
캐시 line의 수명, hit 횟수를 기준으로 캐시 line에 우선순위를 부여한다.
- 즉 캐시 line의 수명, 타입, Hit 횟수 총 세가지의 특징에 대해 우선순위를 부여한다.

Age priority

캐시 라인의 수명에 대한 우선순위이다. 캐시 라인의 나이를 나타내는 변수, 즉 얼마나 오랫동안 있었는지를 나타내는 변수로(recency와 비슷하지만 recency는 어느 시점에 들어왔는지를 나타내는 변수이다.) Age counter를 사용한다. 캐시 메모리에 데이터가 저장된 시점에서 해당 캐시 line의 age counter은 0이 되며 다른 데이터가 들어올 때마다 age counter가 1씩 증가한다. age counter가 해당 캐시 line의 reuse distance ( Preuse distance 의 평균 * 2)와 같아질 때 까지는 다시 접근될것이라고 간주하여 우선순위를 1로 한다. 하지만 age counter가 reuse distance보다 커지면 다시 접근될 가능성이 낮은 데이터라고 간주하여 우선순위를 0으로 낮춘다.
Type priority

Access type이 prefetch일 때 제거 될 가능성이 높았기 때문에 Access type이 prefetch 인 cache line의 우선순위로 0으로 하고 나머지 type에 대해서는 우선순위를 1로 한다.
Hit priority

Hit 경험이 많을수록 자주 사용하는 데이터이기 때문에 우선순위를 높게 해야한다. 따라서 캐시가 재사용 된 경우 (Hit 경험이 있는 경우)에는 우선순위를 1로 하고, 캐시가 재사용 된 적 없는 경우에는 (Hit 경험이 없는 경우) 우선순위를 0으로 한다.
만약 캐시 line의 우선순위가 같을 경우 recency값이 더 큰 캐시 line을 제거한다. recency값이 클수록 퇴근에 access 된 캐시 line이기 때문이다.
5 EVALUATION
IPC Speedup over LRU - 벤치마크
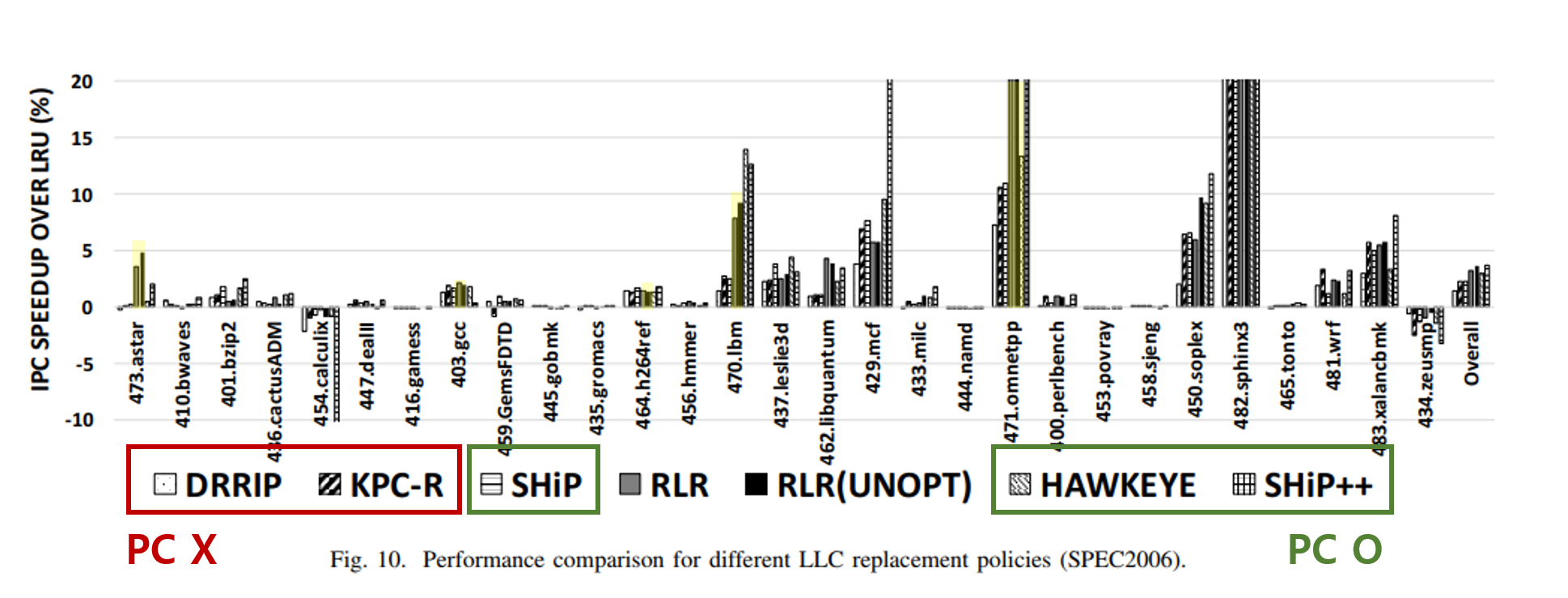
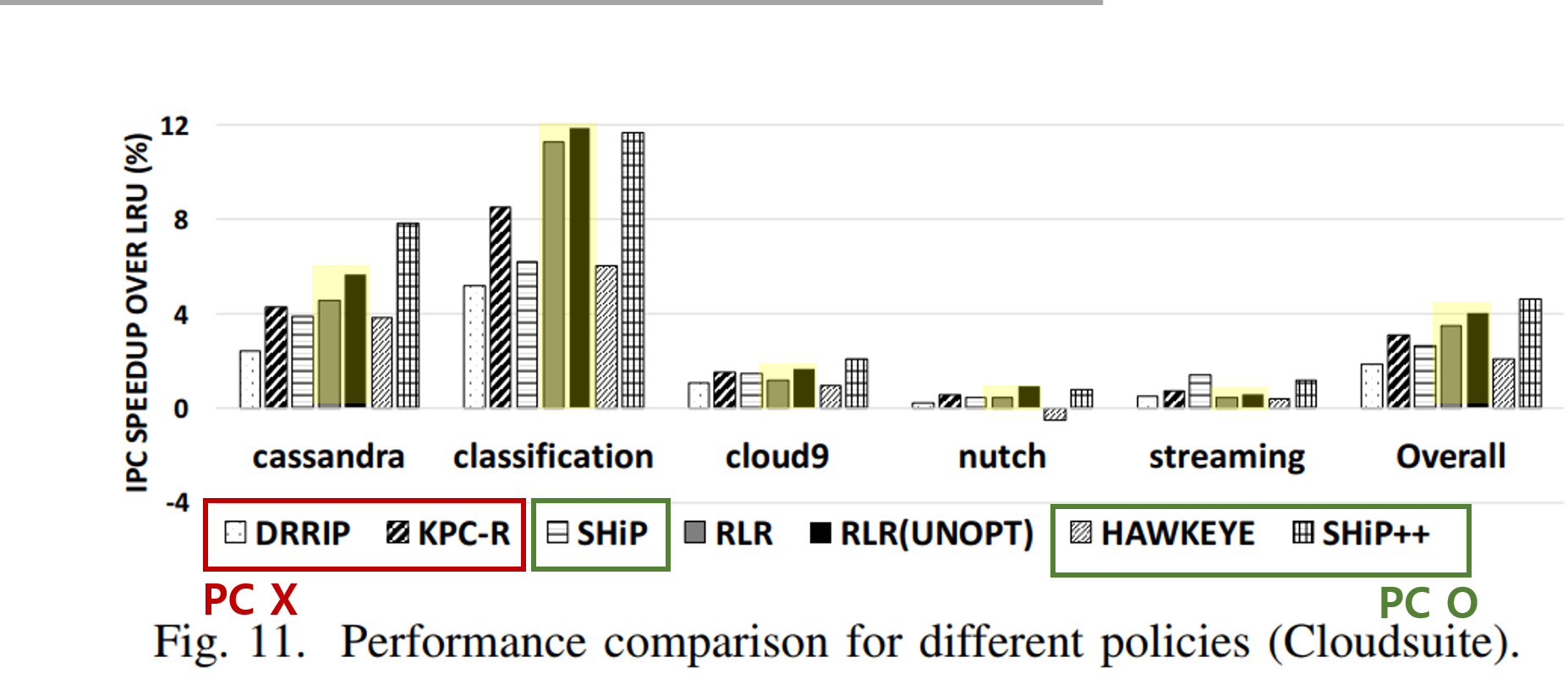
위는 SPEC2006의 벤치마크, 아래는 Cloudsuit의 벤치마크의 성능을 비교한 그래프이다. LRU에 비해 얼만큼이나 속도가 빠른지를 나타낸것으로 RLR은 대부분의 벤치마크에서 다른 PC기반의 알고리즘과 비슷한 속도를 낸다는것을 보여주고있다.
IPC Speedup over LRU - 4core workloads
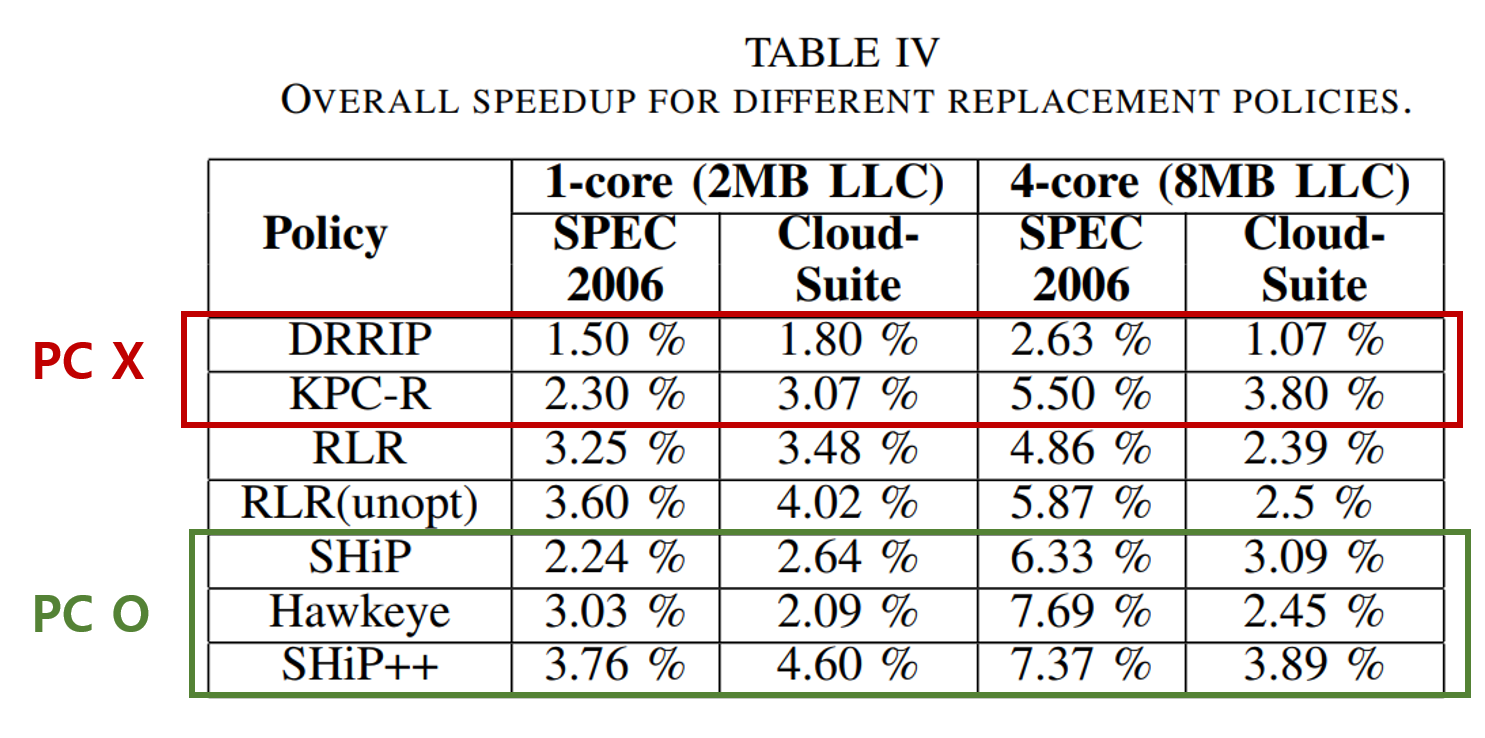
4core 에서는 pc기반의 교체 알고리즘보다 조금 떨어지는 성능이지만 여전히 PC기반이 아닌 교체 알고리즘보다는 좋은 성능을 내는 것을 확인할 수 있다.